
Table of Contents
NOTE
All credit for the slides in the pictures goes to their creators!
NOTE
If you are in one of these pictures and want it removed, please contact me by email (see about/imprint page).
Welcome & Kickoff

On my way to Ceph Day Darmstadt 2018
We got some small sweet breakfast snacks and coffee to start the day off!

Ceph Day Darmstadt 2018 Kickoff
Talks
Ceph Luminous is out what’s in it for you? - John Spray (Red Hat)
Ceph is going to use a new/changed release cadence. The new release cadence is as follows, that a new stable release is made every 9 month. Additionally to that, the upgrade is only supported from version N-2.
Luminous Release
There is a new OSD backend: BlueStore. It is faster (than FileStore?) on HDDs (~2x), SSDs (~1.5x). BlueStore calculates data checksums which can be used for erasure code. This also allows for smaller journals. To further decrease the amount of data saved, in-line compression is possible now.
It is now possible to run RBD & CephFS on erasure coded pools (at least the data pools). There have been significant improvements in efficiency for erasure coded pools. Keep the following points in mind:
- Small writes are slower than replication (more bytes to disk)
- Large writes are faster than replication (fewer bytes to disk)
The Ceph MGR component is now a mandatory part of the cluster. Modules for the MGR are available for zabbix, influxdb, prometheus, etc. Through the move out of certain performance stats collections the MON performance should be improved.

Ceph Day Darmstadt 2018 - Ceph Luminous - Ceph MGR
There has also been a (modernized) dashboard for Ceph, but it is read-only (it is not a configuration tool).
The ceph commands have been cleaned up a lot. ceph status is not so verbose anymore.
An example of “removed” verboseness is the PG status. Previously the PG status was shown for “every” state PGs where in.
But what counts for you, when checking the cluster status:
- How many PGs are healthy?
- How many PGs are in an unhealthy?
This, let’s call “domination”, has also been reduced in the logs (unless otherwise specified by a logging options/flag).
The new AsyncMessenger should remove the need to have to increase the ulimit on nodes because there is now a fixed size thread pool for the messenger.
DPDK from Intel is going to be a way to support new faster storage devices in point of the network, so it won’t be the bottleneck.
DPDK is a set of libraries and drivers for fast packet processing. See https://github.com/ceph/dpdk
OSD balance is a way to move single PGs to other OSDs, which can be a good feature to further balance OSDs either by automated orchestration or manual labor. Some new features though, require Ceph/RBD clients with Luminous or higher.
A lot of overall improvements to RADOS, like require_min_compat_client to “force” a certain minimum client versions (aka no communication with clients lower than VERSION).
CephFS now supports multiple active MDS daemons with that you can scale out your metadata performance by simply adding more MDS instances. (Directory) Subtree pinning allows to isolate certain workloads (directories), by “pinning” directories to specific MDS servers ~= work distribution. I think this is awesome to be used with an orchestration mechanism to distribute certain directories (which are heavily used) automatically to “bigger” MDS nodes/servers. The large directory fragmentation support is now enabled by default.
RGW S3 has now the (AWS) S3 encryption API implemented and dynamic bucket index sharding has been added.

Ceph Day Darmstadt 2018 - Ceph Luminous - RGW Metadata search
It is now also possible to use a tool, like Elasticsearch, to do metadata searches.
ISCSI support has been added for RBD. The kernel RBD module has been updated with the “latest” features, which is awesome.
Mimic
The Ceph MONs will now do/allow for a central configuration of the components. To bring Kubernetes in this, this seems like what is currently going on with the kubelet. The kubelet will soon be able to be configured by the “apiserver”, which will ease the deployment of (many) kubelets.
Optimizations to the PG peering, which will be helpful for users that have network flaps from time to time that cause network “outages”. Improvements for Erasure Coding (EC) for single OSD failures.

Ceph Day Darmstadt 2018 - Ceph Luminous - Other RADOS improvements
Quality of service (QoS) is another constant point of constant work.
Continued development on dmclock, a distributed QoS algorithm (for “speed” reservations).
There is already a promising prototype available.
“Speed” reservations would allow an admin to “reserve” storage speed (Mbit/s) by clients.
Another thing is tiering which has already been in many Ceph releases.
A new redirect primitive has been added. It is like a symlink to data (/an object).
Deduplication is also a topic which will most likely done through hashing.
WARNING Keep in mind the law of your country! At least for Darmstadt it seems that you must store the data the same way the user has by law.
Still a point of research of deduplication is if it should be done inline, async or as an agent.
The Ceph MGR will receive improvements to modules and overall “infrastructure” of it. Additionally to that the rebuild reporting has been improved to show a progress bar instead of only a list of PGs.
ARM builds will be further improved in point of (more) official builds. They are very useful for example for embedded systems that sit directly on a disk or overall cheap ARM servers. To contribute to the “ARM cause” hardware can be contributed to Ceph. If you want to hear more about ARM, this talk from this Ceph Day maybe interesting for your: A flexible ARM-based Ceph solution - Mohammad Ammar (Starline).
Email Storage with Ceph - Danny Al-Gaaf (Deutsche Telekom AG)
Slides can be found at dalgaaf/cephday-Darmstadt-emailstorage GitHub page.
They are using Dovecot with “simple” Network Attached Storage (NAS). Having the following stats:
- ~39 million accounts
- ~1.3 Petabyte of emails
With NFS most operations are to check access to files and checking for existence of files. But trafficwise the most are write and followed by read.
Email size distribution:
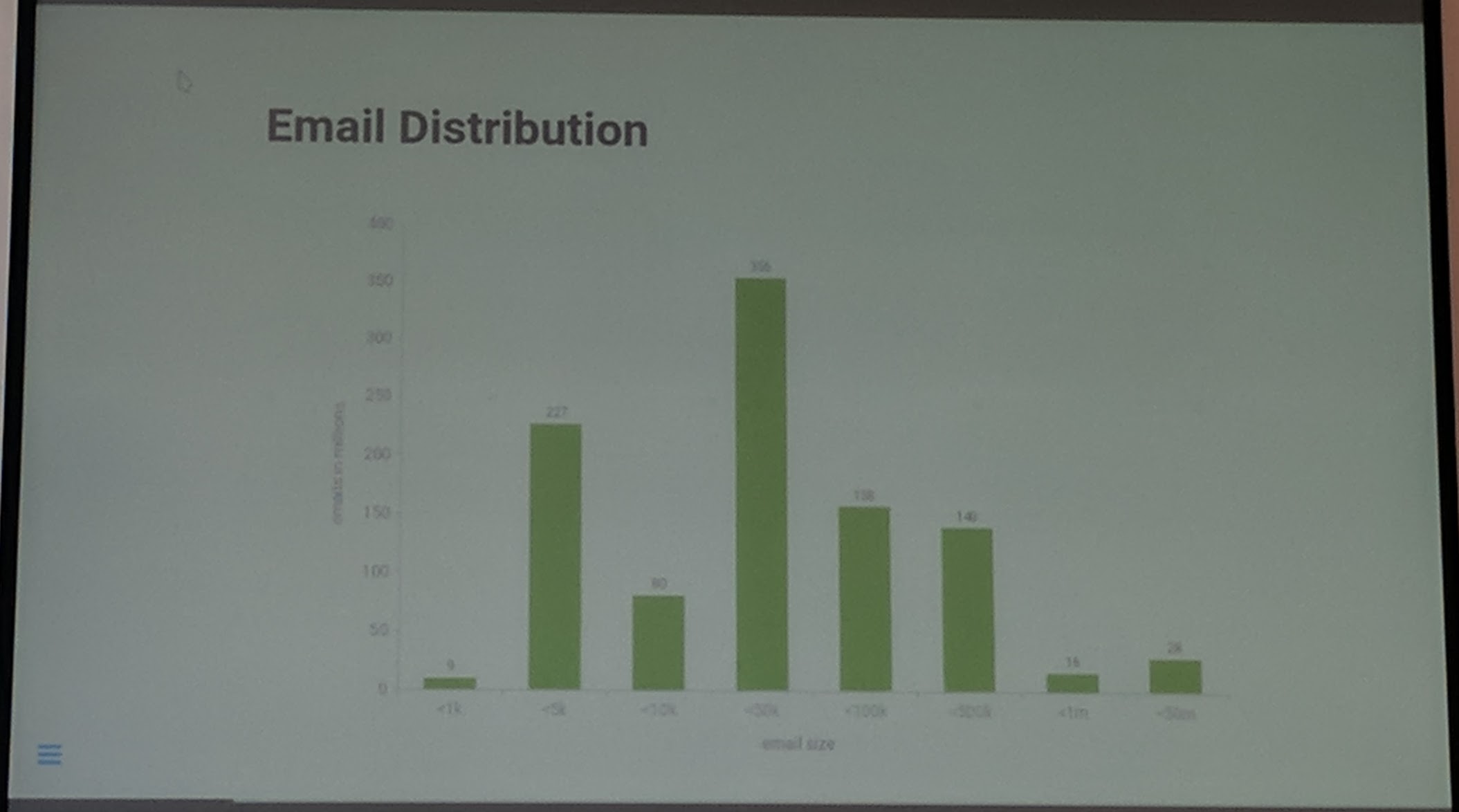
Ceph Day Darmstadt 2018 - Email Storage - Email Distribution
WORM = Written Once Read Many (especially for emails). Depending on which entrypoint (protocol, webmailer) the users go the traffic is different, due to differences in the implementations of IMAP, POP3 protocol and mailer vs webmailer.
Their motivation behind using Ceph is:
- Faster (than NFS)
- Automatic self healing
- Less IO overhead
- Prevent vendor lockin
- Reduce costs with Open Source
CephFS was not an option because of the same issues as with NFS. With NFS and CephFS, mails have to go through “every” POSIX layer of the filesystem before being “written”. Also CephFS requires full access to the storage network to be able to work.
- RBD would be impractical, because of “only one mount” (ReadWriteMany), additionally also the point of again requiring full access to the storage network.
Ceph RGW does not need a direct/“full” storage network access, also it can be secured by a Level 7 Web Application Firewall (WAF).
librados allows for direct access to RADOS. But it is not originally made for mail handling, issues with how to handle cache/indexes came up. Again the security point arose, that librarods requires access to the “full” storage network.
Dovecot has a high market share 72%. There was already an object store plugin available for Dovecot but it is paid by the number of email accounts. Deutsche Telekom’s approach was that closed source was not an option. They have “another” company, named Tallence AG, doing the coding for them.
They will do/did a “migration” in multiple steps: Firs step was to put mails in RADOS directly with a generic email abstraction on top of librados. Metadata and indexes where placed on CephFS.
librmb is a mail object format. Mails are immutable regarding RFC-5322. A simple rmbd tool has been build to get metadata information to be able test it quickly.
It’s open source!: GitHub ceph-dovecot, it is written in C++.
NOTE They most likely chose C++ because of the optimized data path.
The Ceph release they are currently utilizing is Luminous.
Ceph Day Darmstadt 2018 - Email Storage - Ceph Release used
They use commodity x86_64 server hardware for Ceph, which further reduces costs.

Ceph Day Darmstadt 2018 - Email Storage - Hardware Setup
Why do they use such an overkill for CPU and memory in their servers? Because hardware vendors didn’t offer single CPU and “low” memory for the number of drives they would use. To note here for Ceph MDS, it seems work better the more RAM it has available.
They most of the time have two different fire compartments per datacenter.
They have 4 x 10G between the switches:
Ceph Day Darmstadt 2018 - Email Storage - Network Setup
They are testing their setup through:
- Load tests
- Failure scenario tests
- Exiting Ceph tests
One topic to solve for Ceph Erasure Coding (EC) is, to improve especially in point of small writes performance.
When everything works they will move to production, without any impact for the users.
They want to get rid of using CephFS for caches and indexes in the future too.
Summary of the move to Ceph:
- Ceph can replace NFS (in a good way).
- librmb and Dovecot rbox are Open Source projects.
They mentioned that data deduplication is potentially legally forbidden for user data.
Email Objects in RADOS - Peter Mauritius (Tallence AG)

Ceph Day Darmstadt 2018 - Email Objects - Dovecot Mail Storage
Dovecot has a good plugin architecture which allows to easily write and integrate a plugin. They use CephFS for the users mail and mailbox directory hierarchy, but not for the actual mails. Mails are saved through librados directly as an object in kind of a hybrid storage, as the caches and indexes are still maintained by Dovecot on CephFS.

Ceph Day Darmstadt 2018 - Email Objects - What will be stored?
A lot of xattr/omap on an OSD (more than millions), may lead to an unstable OSD.
Ceph at SAP – How to build a cattle cloud - Marc Koderer (SAP) / Jan Fajerski (SUSE)
Building a cloud native application/service is not easy.
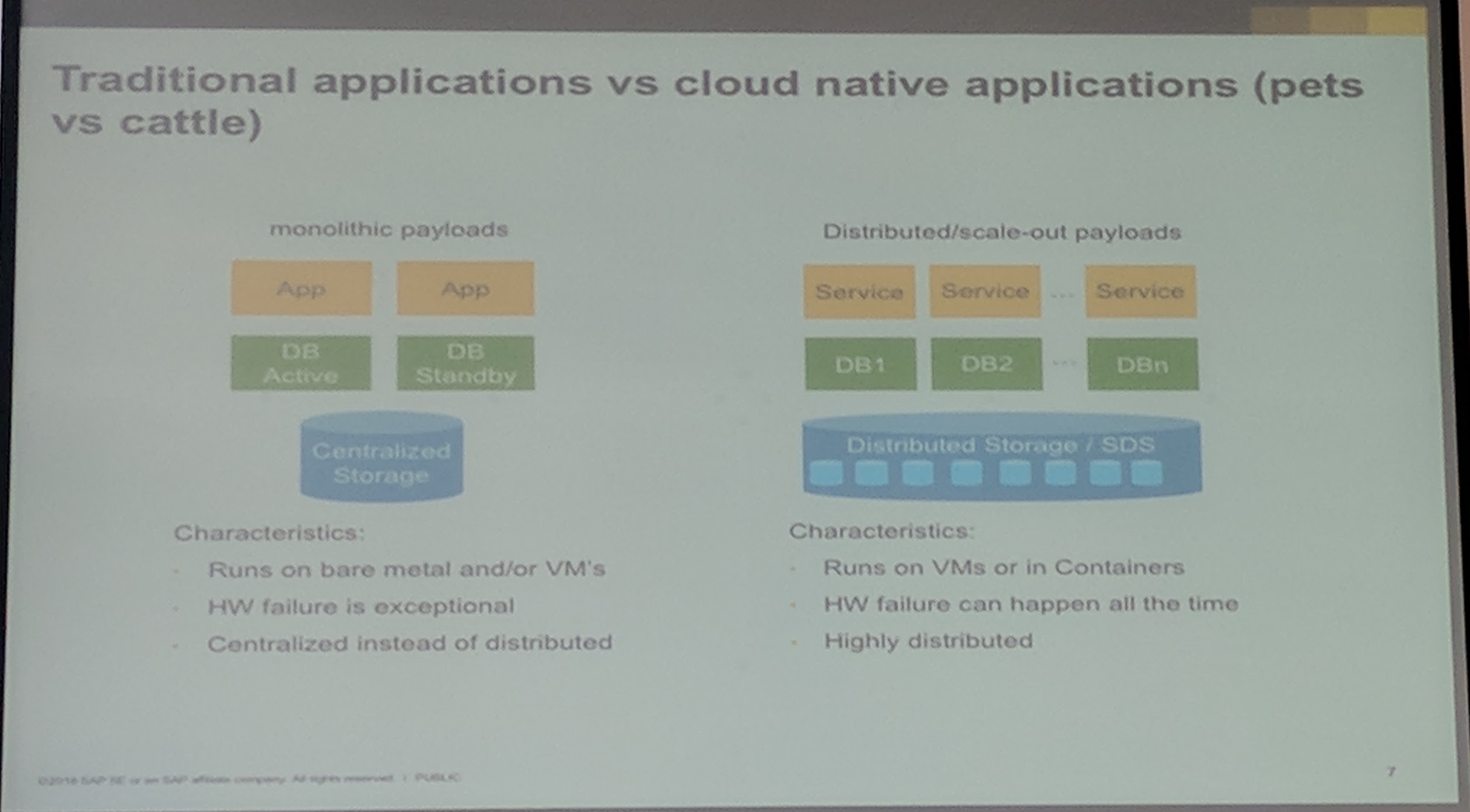
Ceph Day Darmstadt 2018 - Ceph at SAP - Traditional vs cloud native Applications
To protect a Ceph object store, you should start at the application layer, to limit the connections and have a “loop back off” for GET/POST/PUT, etc. If not implemented in the application, can also be done in the Loadbalancers by utilizing rate limiting and even blacklisting.

Ceph Day Darmstadt 2018 - Ceph at SAP - Ceph Overview
Every availability zone has the same store capacity and hardware. For replication they use 2x 25Gbit for each backend and frontend. Their setup is designed to compensate the outage of one availability zone.
Again mentioned here is that through the removal of the filesystem POSIX layer (when FileStore is used) is, that BlueStore is faster.
They use GitHub SUSE/DeepSea for deployment which is based on/uses Salt Stack. A goal of the deployment process is to minimize the manual work. They have different stages for their deployments, example stage 0 is that all hardware is there and at the same state as every node (updates, etc).
For configuration of storage with Ceph, they have created something called “Storage profiles” these files are generated through their DeppSea hardware discovery and contain the disk configuration for each server/host.

Ceph Day Darmstadt 2018 - Ceph at SAP - Storage Profiles
Ceph RGW with S3 support is especially good for applications because it is compatible with multiple cloud environments where S3 is offered as a service. For example, you can use Ceph as S3 on premise and use AWS S3 in the AWS cloud.
Ceph for Big Science - Dan van der Ster (CERN)
They generate about 10 GB per second, and about 50 Petabyte per year.

Ceph Day Darmstadt 2018 - Ceph for Big Science - Scale Testing
They use virtual NFS filers currently with about ~60TB and ~30 servers. But this doesn’t really scale performance wise.

Ceph Day Darmstadt 2018 - Ceph for Big Science - CephFS: Filer Evolution
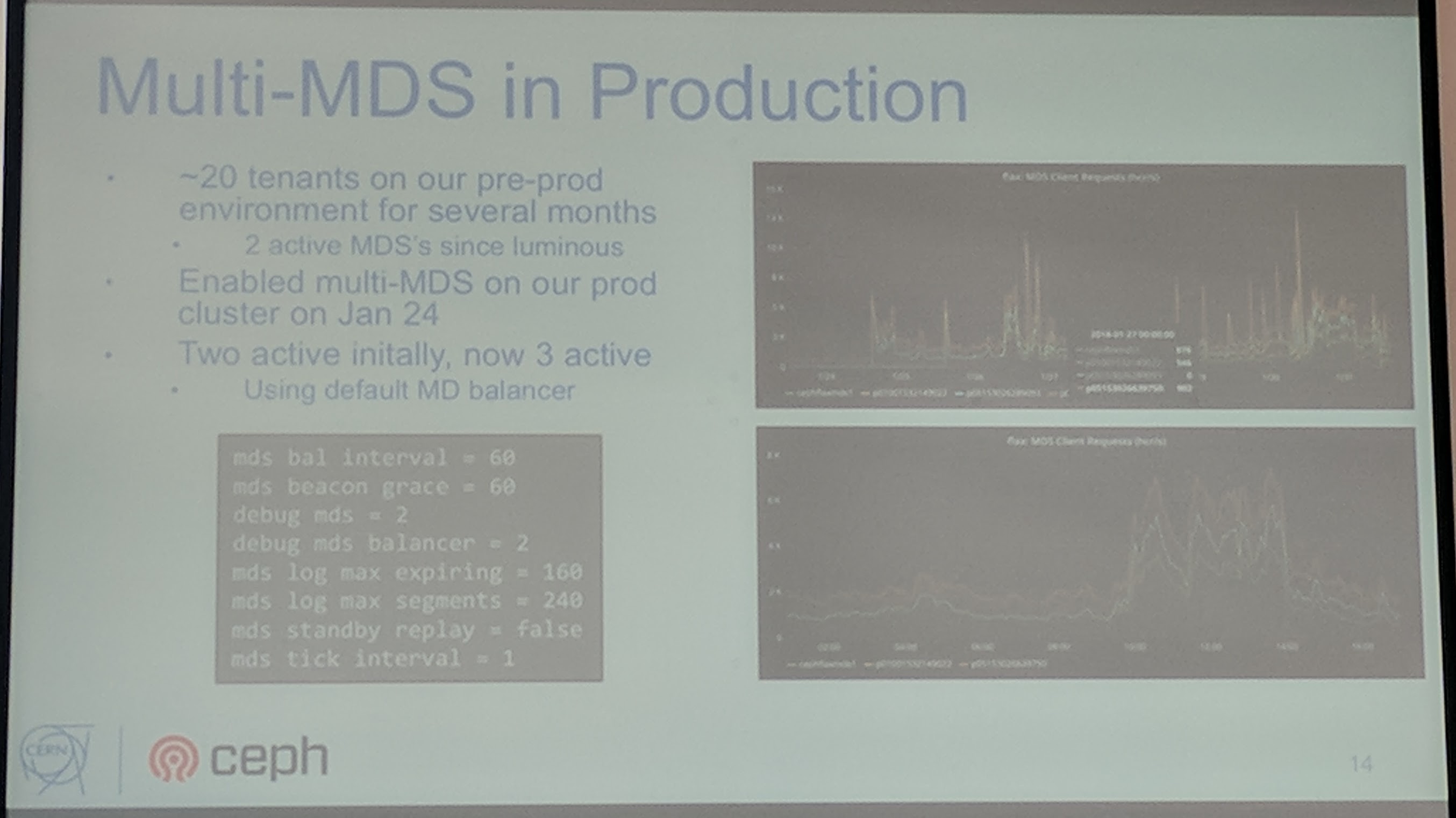
Ceph Day Darmstadt 2018 - Ceph for Big Science - Multi-MDS in Production
They scaled up to two MDS with Luminous upgrade, as the multi MDS feature has been added.
CERN is building their HPC clusters from commodity parts to reduce costs. IO-500 is a top list for fastest storage but not only the heroes should be on there, but also the anti-heroes with not so fast storage. The benchmarks for it will be published with the tuning parameters and configuration used.
Ceph RGW - S3 @ CERN They use HAProxy to balance the load in front of the Ceph RGWs, to mitigate Ceph RGW restarts and direct traffic of “special” buckets to dedicated Ceph RGW instances.
Meletdown/Spectre had something good for them (at least the storage team), as now they Hypervisors are not accessing the Ceph clusters with an old client version anymore.
There is a module in Luminous which allows to re-balance PGs from node to node, there are some things though that need to be kept in mind depending on which mode is used.

Ceph Day Darmstadt 2018 - Ceph for Big Science - ceph balancer on
If you have activating+rempped PGs, you should checkout the Ceph issue #22440New pgs per osd hard limit can cause peering issues on existing clusters.
A flexible ARM-based Ceph solution - Mohammad Ammar (Starline)
ARM has a high cost effiency, because the prices are very low due to high competition in this hardware field. Attempts to run SoC (System on a Chip) systems with Ceph, can be seen in HDDs that come with an ARM processor. There is also a broad range of ARM full server configurations available. Another point is that has already been “demonstrated” with Raspberry Pi is, that ARM doesn’t require much space to run.

Ceph Day Darmstadt 2018 - A flexible ARM-based Ceph solution - Hardware Advantages
It is feasible to run one such server as an entry level storage. To scale up services such as Ceph MONs, OSDs would be pinned/moved to other servers in the rack (example was with 3 servers each 1U, having each 1 Ceph MON).
Using ARM with Ceph combines the scalability and flexibility of Ceph with the cost efficiency and “speed” (of many servers) of ARM. With the cost effiency also comes power efficiency, that further reduces costs.
Five years of Ceph and Outlook - Lars Marowsky-Bree (SUSE)
The direction is set by the people who code or the people who pay people to code. The SUSE Enterprise Storage is keeping up in a good manner with the upstream project and release cycle.

Ceph Day Darmstadt 2018 - Five years of Ceph and Outlook - SUSE Enterprise Storage 5
The “Enterprise” part here mostly seems to come from a) support and b) orchestration (framework) around Ceph. A good orchestration layer helps with tasks such as upgrading FileStore OSDs to BlueStore.
For each filesystem, block storage and block use case, Ceph is a potential candidate.

Ceph Day Darmstadt 2018 - Five years of Ceph - Focus areas of SUSE Enterprise Storage 6
CIFS/Samba is not going away too soon in corporate environments.

Ceph Day Darmstadt 2018 - Five years of Ceph - Advice nobody asked for (and I wish they did)
You can’t just put in Ceph and never touch it again. It is, as always, with software, it grows and changes aka updates. Don’t skimp on the network layer (you should at least have 40G network for Ceph). Heterogeneous environments are a good idea to not suffer a whole cluster failure on a bug for example in the network card.
There are more possibilities to meet with the Ceph community this year.
Ceph Day Darmstadt 2018 - Five years of Ceph - Interested? Join us for more!
Ceph Management and Monitoring with openATTIC - Kai Wagner (SUSE)
There have been a lot of changes from the project start till now to the user interface. Since 2017 they have only focused on “Ceph only” (and first).
For deployments they are using Salt. They chose it as it is fast, allows for parallel execution and has a good scalability. Salt here is used with DeepSea for orchestration. openATTIC allows management of iSCSI tagets via lrbd. For MONitoring part it deploys Prometheus and Grafana.
After the decision to be a “Ceph only user interface”, they set new goals such as:
- To be a Open Source Ceph management and monitoring interface.
- Scaling without becoming overwhelming.
Some features of openATTIC:
- Stateless
- Ceph RGW management
- Web-based configuration
- Support for Ceph Luminous release features
- And much more..
Outlook to the future of openATTIC and Ceph MGR:

Ceph Day Darmstadt 2018 - Ceph Management and Monitoring - openATTIC goes upstream
They want to go upstream with the user interface/dashboard: “Change the logo”, become the new default dashboard for Ceph.
Ceph Performance on New Intel Platforms and SSDs - Mohamed Elsaid (Intel)
Intel® tries to be the “power” behind the hardware of today’s storage software/vendors.

Ceph Day Darmstadt 2018 - Ceph Performance on New Intel Platforms and SSDs - Ceph Benchmarking with Intel Purley, Skylake & Optane
It was a very hardware heavy talk. A lot of performance diagrams. Not that this was not interesting, but if someone is searching appropriate hardware for the task he should get this information without a problem from Intel or other hardware vendors.
They have put up a site with part of these informations, see Intel® Storage Builders.
NOTE Intel still doesn’t get why everyone is “pissed” at them.. One of the X bugs, that is only working on Intel, is a good reason to be “pissed” at them. :)
10 ways to break your Ceph cluster - Wido den Hollander (42on.com)

Ceph Day Darmstadt 2018 - 10 ways to break your Ceph Cluster - Thank you!
- Wrong CRUSH failure domain - Don’t assume it is working, test the failover (before going live with it)!
- Decommissioning a host - A disk failed in another system causing the data to get corrupt, during the removal of the other host. Only remove a node when the cluster is healthy (and has enough failover capacity).
- Removing
logfiles in MON’s data directory - This deletes actual data required for the MONs to run. When backfills happen, the MONs data directory will grow (8 days backfill, grew to 45GB). - Removing the wrong pool - Double check before removal of “anything”, as when a pool is gone, it is gone for real.
- Setting the OSD
nooutflag for a “long time” - Don’t run a system inHEALTH_WARNstatus (other ways would be to set minimal replicated data available to at least two or more). - Mounting XFS with
nobarrieroption - It can cause the FS to be corrupted and Ceph data lost. - Enabling Writeback on HBA without BBU - This should not be done unless you have a BBU!
- Creating too many Placement Groups - Can cause an overdoes of the Ceph cluster in cases like power/node failure.
- Using 2x replication - If a node fails while you are doing for example maintenance, the data on the maintained node is outdated due to new writes to the other node PGs.
- Underestimating Monitors - Use good hardware with enough resources (even though they don’t use that much CPU or memory) the hardware should not fail easily (using SD-cards for MONs). Go for 5 MONs instead of backing the MONs up.
- Updating Cephx keys with the wrong permissions - This can cause a huge failure for a cluster, the example shown was OSDs key without write permission to a pool, which caused corrupted filesystems for VMs.
A reasonable OSD count should be chosen depending on the information given on the Ceph PG calc page.
It was funny to hear the stories, as almost everyone had already experienced such a story for himself at one point in time.
Development update: ceph-mgr and kubernetes - John Spray (Red Hat)

Ceph Day Darmstadt 2018 - Development update: ceph-mgr and kubernetes - Managing Ceph in containers: ceph-mgr and Rook
Currently managing Ceph is kinda fractured depending on how you deploy Ceph .
“Why hasn’t everyone switched to Containers?”
Ceph Day Darmstadt 2018 - Development update: ceph-mgr and kubernetes - Glorious Container Future
Kubernetes is a tool to run containers. A tool for container orchestration which keeps a lot of points, like (cpu and memory) resources, in view while scheduling containers.

Ceph Day Darmstadt 2018 - Development update: ceph-mgr and kubernetes - Rook

Ceph Day Darmstadt 2018 - Development update: ceph-mgr and kubernetes - How can we re-use the Rook operator
Depending on how you see it, the “user interface” through YAML is problematic especially for destructive options where an user normally would be asked to confirm by adding multiple flags to the command.
John Spray kind of proposes to use Rook “only” to run the infrastructure around and not directly talk with Ceph except with the Ceph MGR.
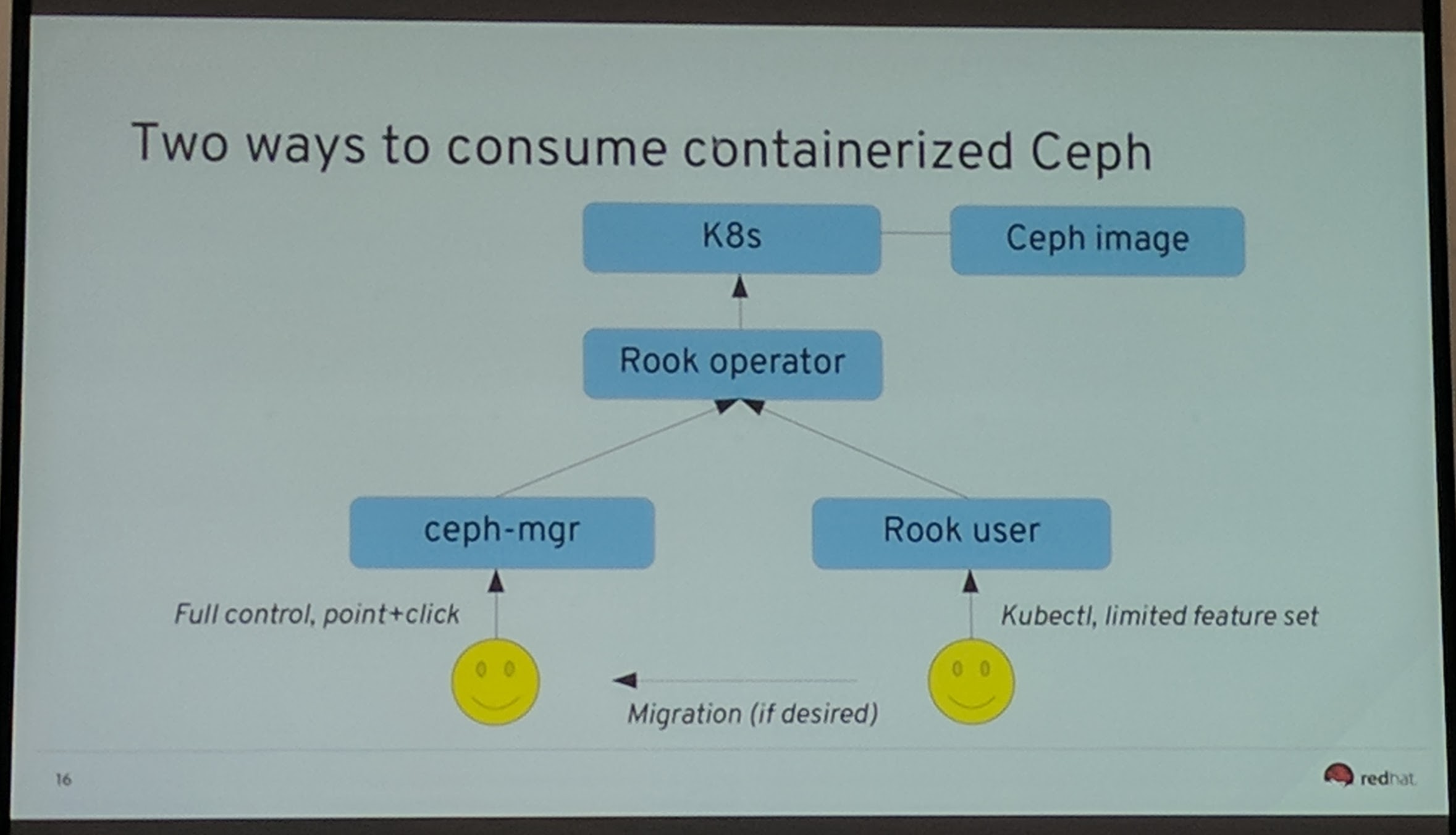
Ceph Day Darmstadt 2018 - Development update: ceph-mgr and kubernetes - Two ways to consume containerized Ceph
Rook is partly for the “Just give me the storage” people within and for the Kubernetes cluster.

Ceph Day Darmstadt 2018 - Development update: ceph-mgr and kubernetes - What doesn't Kubernetes do for us?
The plan is unwind Rook to also allow external clusters to be used with Rook and do some pieces using the Ceph MGR instead of Rook or both. More discussions on that are currently taking place and will continue from what I know.
Overall there has been work on improving MGR modules like pg_num management and openATTIC dashboard v2 upstream to Ceph ongoing.
Everyone can Build and Maintain a Ceph Cluster with croit - Paul Emmerich (croit)
They are building a plattform to “deploy, use, mamnage and monitor” Ceph cluster(s).
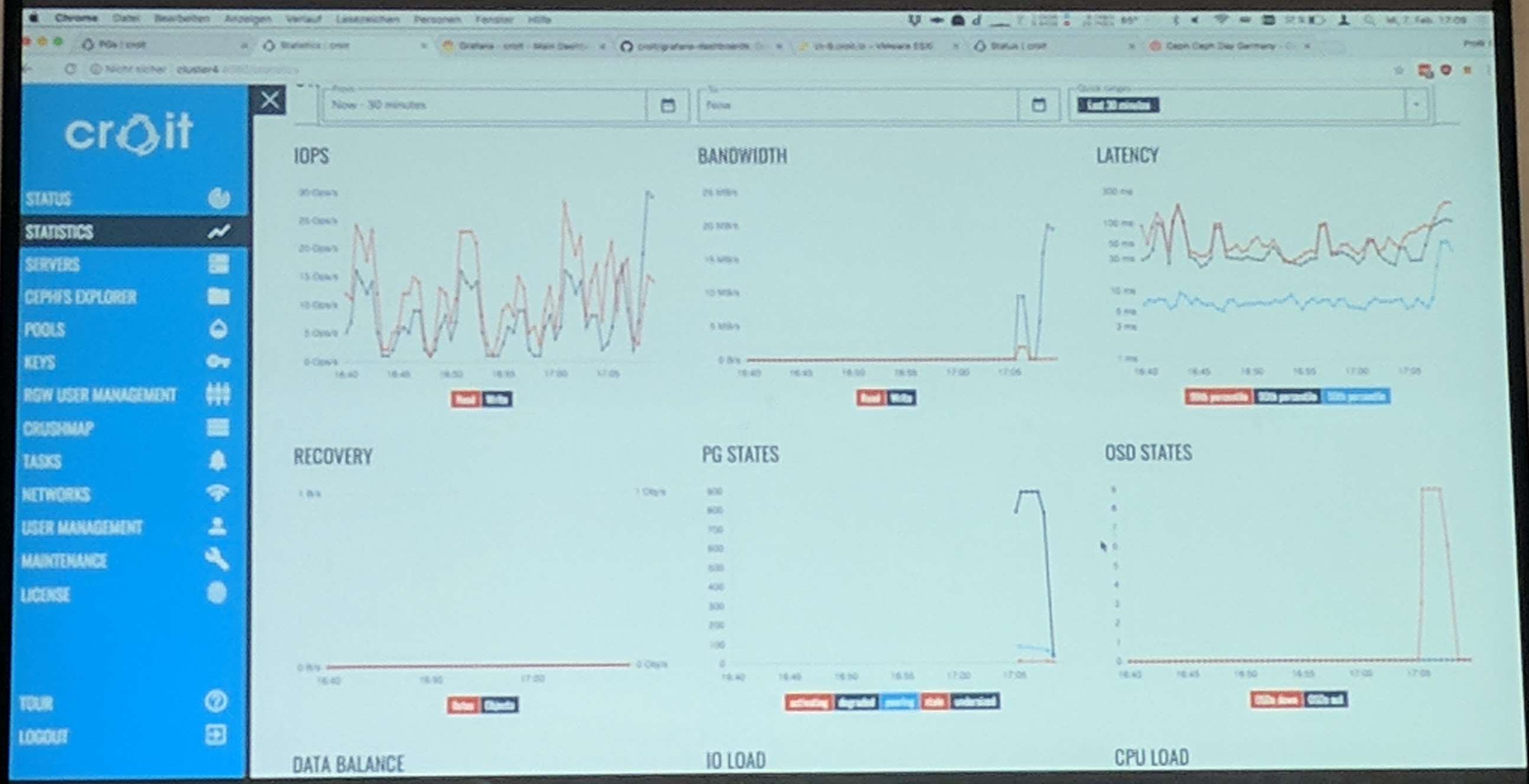
Ceph Day Darmstadt 2018 - Everyone can Build and Maintain a Ceph Cluster with croit - croit Webinterface
The shown demo was of their latest croit release. The web interface looks nice (and is responsive) from what I have seen in the demo. It allows to manage and monitor every Ceph service (from MON to RGW) through the user interface, but also through a REST API.
SSD-only Performance with Ceph - Sven Michels (sectoor GmbH)

Ceph Day Darmstadt 2018 - SSD-only Performance with Ceph - The Limit
The limit for SSDs (or overall non-spinning disks) is mostly because of the Ceph OSD code. A solution for that is to rewrite the Ceph OSD code with non-spinning disks in mind. Ceph will be the limit most of the time before the hardware, when using non-spinning disks.
If you want a full performance Ceph cluster, this current limit should be kept in mind. Also to note here, that work in the OSD code is currently ongoing for the next Ceph release (Mimic).
Q&A Session

Ceph Day Darmstadt 2018 - Q&A Session - Speaker Lineup
So many talks in one day at one event. Awesome! I’m happy to go there next year again and maybe even as a speaker.
Summary
It was very informative listening to all the talks. It was especially interesting to hear about the different use cases of Ceph (librados, RBD, CephFS and RGW). As always it was interesting talking and hearing from Ceph users and devs, what they are doing with Ceph.
Have Fun!
Intel and the Intel logo are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries.