
Table of Contents
NOTE
All credit for the slides in the pictures goes to their creators!
NOTE
If you are in one of these pictures and want it removed, please contact me by email (see about/imprint page).
Slides
The slides of the talks can be found here: Ceph Community presentations channel - SlideShare.
Welcome & Kickoff

Ceph Day Berlin 2018 - Cloudical team arrived at the conference center
I arrived with my colleagues from Cloudical at the Ceph Day Berlin location, which at the same time was the location for OpenStack Summit.

Ceph Day Berlin 2018 - Ceph Day Sponsors
Sage Weil announced that the Ceph Foundation has been founded with help from the Linux Foundation.

Ceph Day Berlin 2018 - Ceph Foundation
Cephalocon Barcelona has been announced. It will take place just “before” KubeCon and just shows that the Ceph team wants to be storage for cloud and containers.

Ceph Day Berlin 2018 - Cephalocon Barcelona announcement
Talks
State Of Ceph, Sage Weil, Red Hat

Ceph Day Berlin 2018 - Ceph Release Schedule Overview
There will be a telemetry module for the Ceph MGR but it will be opt-in. The telemetry data will be anonymized and only “basic” stats such as OSD count, cluster size and so on are transmitted.
To help Ceph clusters with their reliability, features have been added to take the health of devices/disks into account. Disk failure prediction can be used to preemptively move data to other disks/servers before a failure to reduce recovery time and cluster load.
The Ceph MGR in general and the Ceph MGR dashboard module have been further improved by John Spray. Additionally to the Ceph MGR becoming more and more stable, the REST API module for the MGR has been improved. The REST API isn’t completely “there” yet, but it is actively being worked on.

Ceph Day Berlin 2018 - State Of Ceph, Sage Weil, Red Hat - Automation and Management

Ceph Day Berlin 2018 - State Of Ceph, Sage Weil, Red Hat - Orchestrator Sandwhich

Ceph Day Berlin 2018 - State Of Ceph, Sage Weil, Red Hat - Kubernetes Above and Below

Ceph Day Berlin 2018 - State Of Ceph, Sage Weil, Red Hat - Rook
The goal for Ceph in Kubernetes is to further go the cloud-native way by making it more and more easy to have storage for containers.
ceph top is like top but for Ceph cluster. It will show you the current “load”/usage of the whole Ceph cluster.
cephfs-shell is a command cli which allows to work with the CephFS without “mounting” it. That is perfect for quickly putting files, directories and setting quotas on a CephFS through scripts/automation.
Project Crimson is looking into re-implementing the OSD data path for better performance, with a focus on “new” devices, e.g., flash and NVME storage.
For new modern IT infrastructures, it is planned to “Reframe Ceph RGW”. This is done to make it more suitable for modern IT infrastructures which most of the time rely on multiple cloud providers/datacenter.

Ceph Day Berlin 2018 - State Of Ceph, Sage Weil, Red Hat - Hardware is changing
RGW federation/sync can allow you to have global user and bucket namespaces in sync over multiple Ceph RGW clusters/zones. RGW sync (now) available to e.g., sync an on-premise Ceph RGW cluster with an AWS S3 for “backup” or just keep two (or more) Ceph RGW clusters in sync.
Managing and Monitoring Ceph with the Ceph Manager Dashboard, Lenz Grimmer, SUSE

Ceph Day Berlin 2018 - Managing and Monitoring Ceph with the Ceph Manager Dashboard, Lenz Grimmer, SUSE - Title Slide
NOTE He has a big Rook sticker on his laptop, which is totally cool as they are currently nowhere available anymore. :-)
They mentioned at last Ceph Day Germany in Darmstadt that the dashboard was available now and is hugely inspired by the OpenATTIC project. So thanks for them to put the work into the official Ceph MGR dashboard module!
They have more features coming up for the Ceph Nautilus release. A big part will be to allow even further configuration over the web with ease.

Ceph Day Berlin 2018 - Managing and Monitoring Ceph with the Ceph Manager Dashboard, Lenz Grimmer, SUSE - Dashboard v2 Overview (Mimic)
I’m especially happy to see the in-built SAML2 support and the auditing support which will be useful for companies.

Ceph Day Berlin 2018 - Managing and Monitoring Ceph with the Ceph Manager Dashboard, Lenz Grimmer, SUSE - New Dashboard features for Nautilus
You can also have a per server overview page with metrics displayed through Grafana.
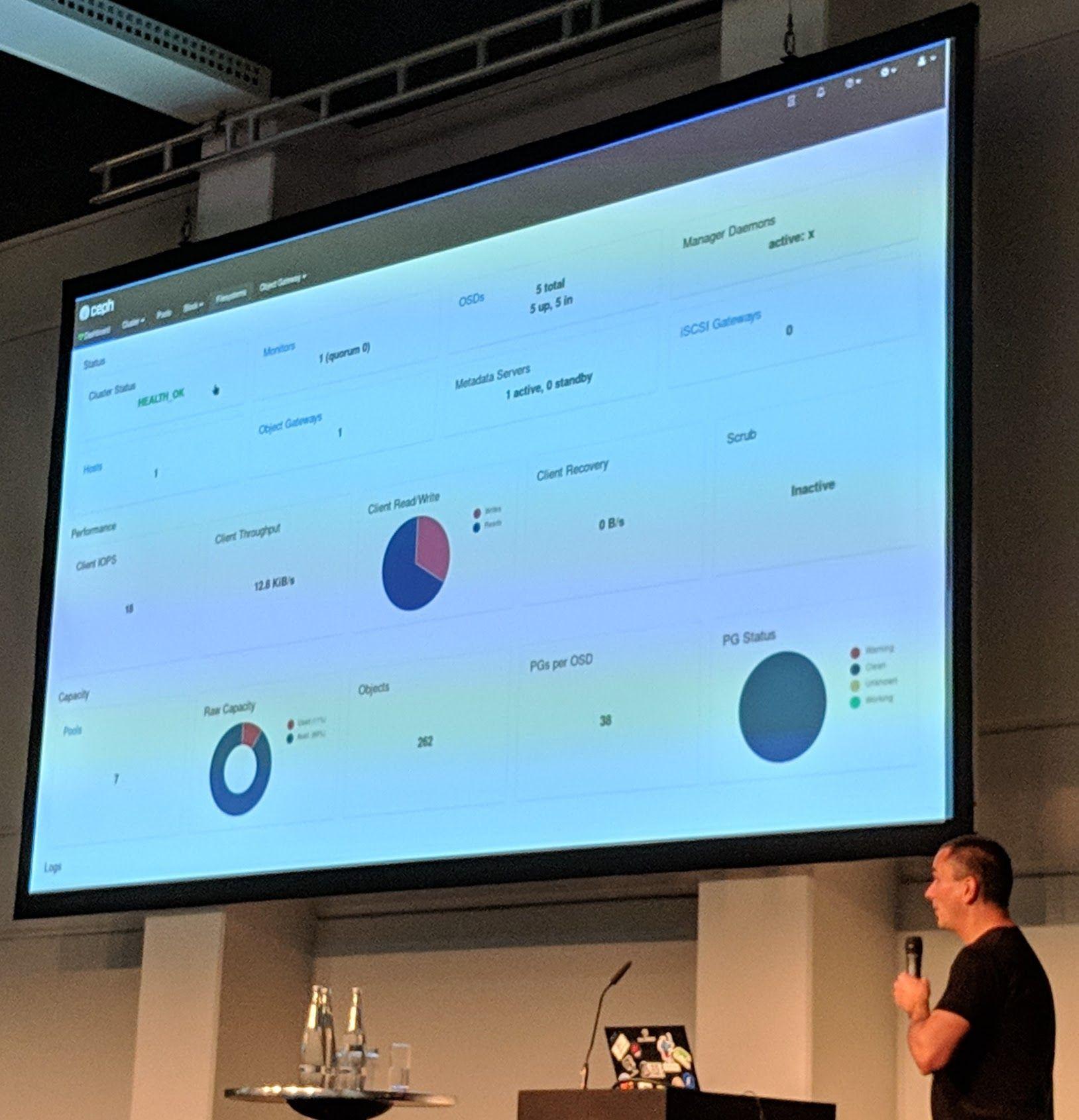
Ceph Day Berlin 2018 - Managing and Monitoring Ceph with the Ceph Manager Dashboard, Lenz Grimmer, SUSE - Dashboard Screenshot #1
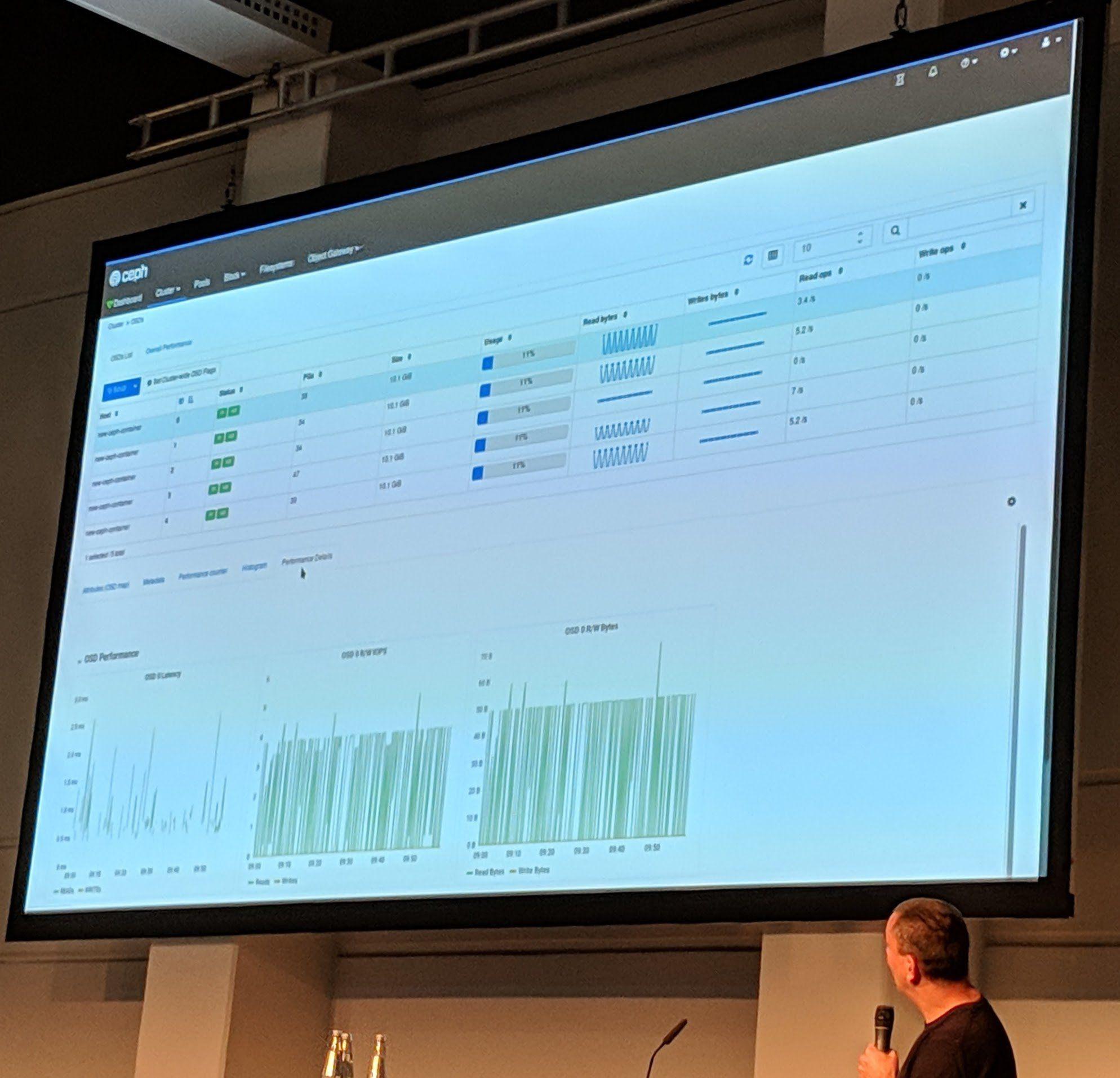
Ceph Day Berlin 2018 - Managing and Monitoring Ceph with the Ceph Manager Dashboard, Lenz Grimmer, SUSE - Dashboard Screenshot #2
Next to “just being a dashboard”, as mentioned earlier there is a focus on allowing a user to make changes to the Ceph config through the Ceph MGR dashboard.
Creating snapshots, clones of rbd images is now also possible through the dashboard.
Even if it is a small thing, thanks to a user contribution You can now see as which user you are logged into the dashboard now.
To summarize, the dashboard can not only show but can also create, modify and also delete “things” in Ceph and edit configurations.
An outlook for the dashboard is to integrate the upcoming orchestration layer of the Ceph MGR.
Building a Ceph Storage Appliance That’s Cooler Than a Dog, Phil Straw, SoftIron

Ceph Day Berlin 2018 - Building a Ceph Storage Appliance That's Cooler Than a Dog, Phil Straw, SoftIron - Title Slide
SoftIron does a lot of thermal analysis of servers.
When they got their new thermal camera, next to taking pictures of dogs with it, they took pictures of their competitors and their own servers. They do that to see their server cooling optimization against the competition:

Ceph Day Berlin 2018 - Building a Ceph Storage Appliance That's Cooler Than a Dog, Phil Straw, SoftIron - 'And the second thing?' - Using thermal camera on servers
“Power is heat”, Power costs money, cooling also costs money = A lot of money
If the design of the servers is optimized for “being cool”, one can potentially get back parts/all of their costs of the equipment back through saving on cooling costs. Though in most cases this would require separate datacenter rooms for the optimized servers with less cooling.
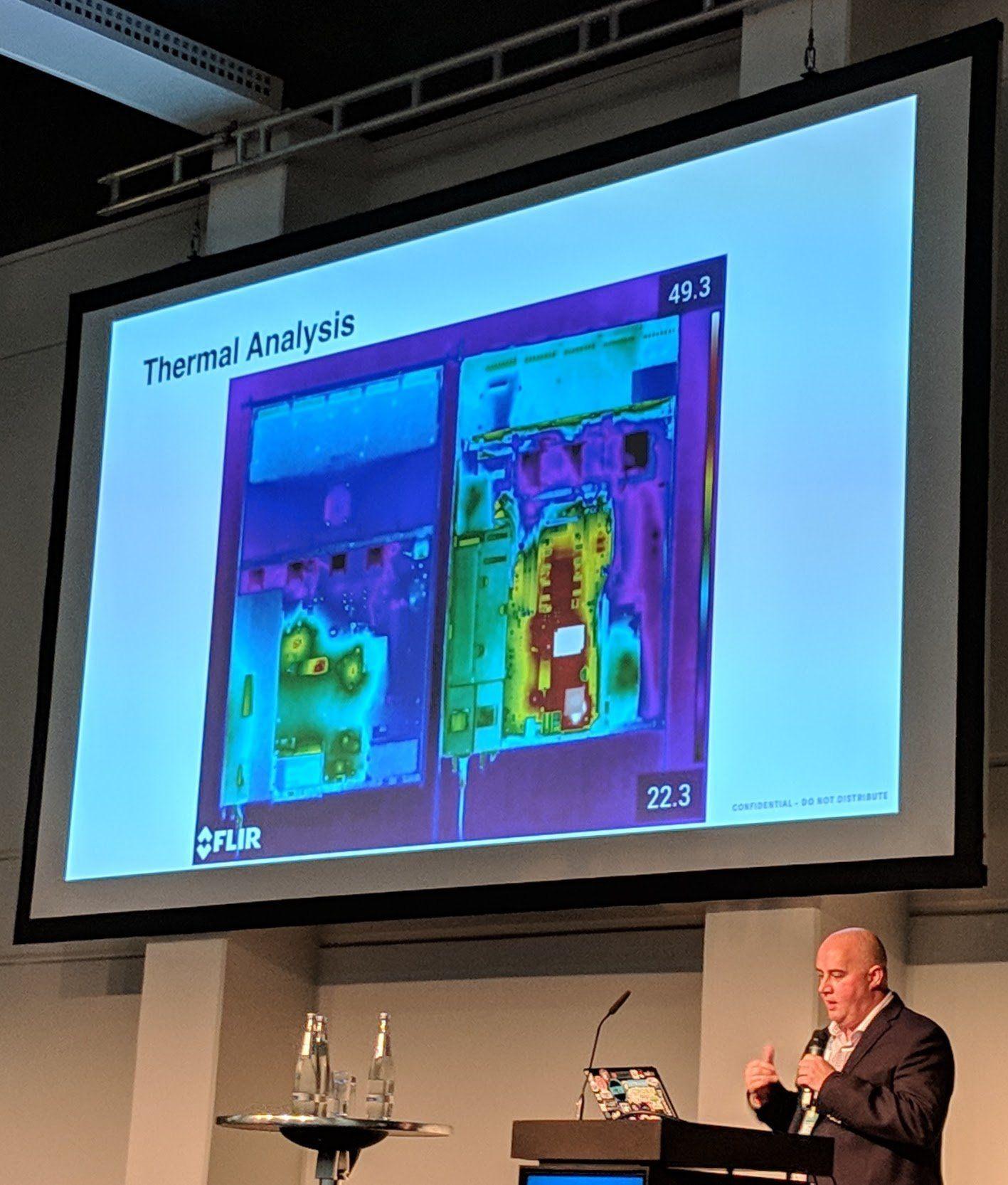
Ceph Day Berlin 2018 - Building a Ceph Storage Appliance That's Cooler Than a Dog, Phil Straw, SoftIron - 'Thermal Analysis' server comparison

Ceph Day Berlin 2018 - Building a Ceph Storage Appliance That's Cooler Than a Dog, Phil Straw, SoftIron - 'Derivation of "Dog Power"- Rest'
A round of applause for their dog.

Ceph Day Berlin 2018 - Building a Ceph Storage Appliance That's Cooler Than a Dog, Phil Straw, SoftIron - 'How do we do it?'
In the end their goal is to have “cool” servers which can “quickly” get back the costs through the servers reduced cooling needs.
Unlimited Fileserver with Samba CTDB and CephFS, Robert Sander, Heinlein Support
NOTE
As this isn’t really a topic which falls into my interest area. I’d recommend to checkout the full slides of the talk on the SlideShare. Now have a few pictures without too much comments from my side:

Ceph Day Berlin 2018 - Unlimited Fileserver with Samba CTDB and CephFS, Robert Sander, Heinlein Support - 'Concept'

Ceph Day Berlin 2018 - Unlimited Fileserver with Samba CTDB and CephFS, Robert Sander, Heinlein Support - 'CTDB - clustered trivial database'
Ceph implementations for the MeerKAT radio telescope, Bennett SARAO, SKA Africa

Ceph Day Berlin 2018 - Ceph implementations for the MeerKAT radio telescope, Bennett SARAO, SKA Africa - Title Slide
After some technical difficulties, he started talking about their work with Ceph at SKA Africa.
“All radio telescopes have received less energy than a snowflake hitting the ground.”
This comment just makes it more and more interesting of how sensitive the radio dishes must be and with that how much data is coming from the sensors.
With more radio dishes the quality of pictures generated from the observations increases, resulting in a picture of the “sky”/universe which is more and more clear.

Ceph Day Berlin 2018 - Ceph implementations for the MeerKAT radio telescope, Bennett SARAO, SKA Africa - 'A fuller picture'
All these radio dishes create an enormous amount of data which needs to be saved, this is where Ceph comes into play.

Ceph Day Berlin 2018 - Ceph implementations for the MeerKAT radio telescope, Bennett SARAO, SKA Africa - 'Radio Telescopes - In a nutshell'
They have tons of data flowing in from the radios dishes which doesn’t only need to be written but also read again and worked on in a timely manner. A problem they had to solve is the data transfer between the radio dishes and the datacenter, which is over 900 kilometers away. They shielded their data lines so that it “survives” the 900 kilometer transfer.
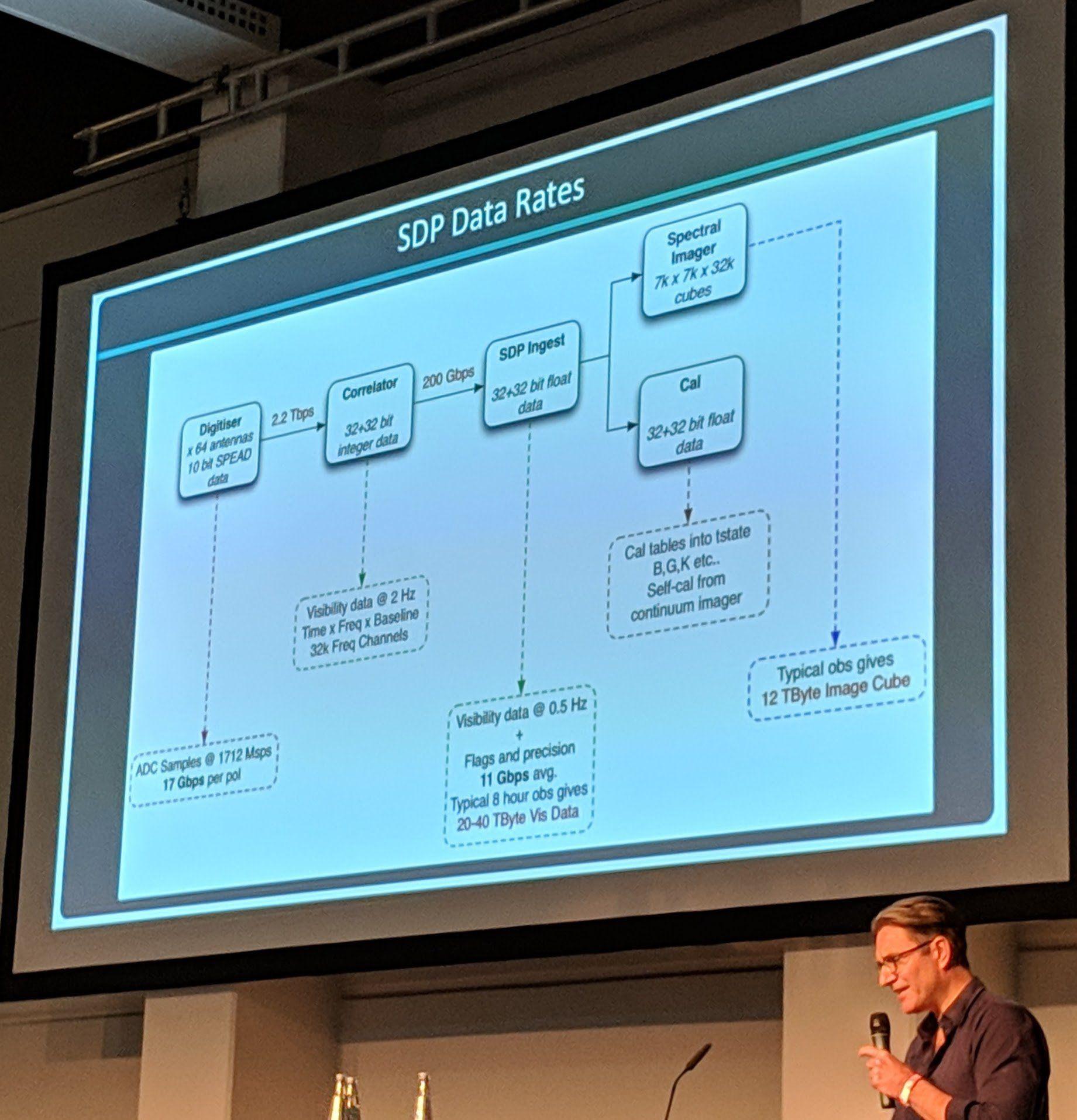
Ceph Day Berlin 2018 - Ceph implementations for the MeerKAT radio telescope, Bennett SARAO, SKA Africa - 'SDP Data Rates'
What I didn’t think is that they use Ceph RGW S3 storage. It just shows how good object storage can be for such amounts of data in their use case.
As they had project budget problems, because of the “decline” of the African dollar in comparison to the US dollar, they used available government programs for such technological projects which brought them together with local IT companies to save costs for the hardware used at the project.
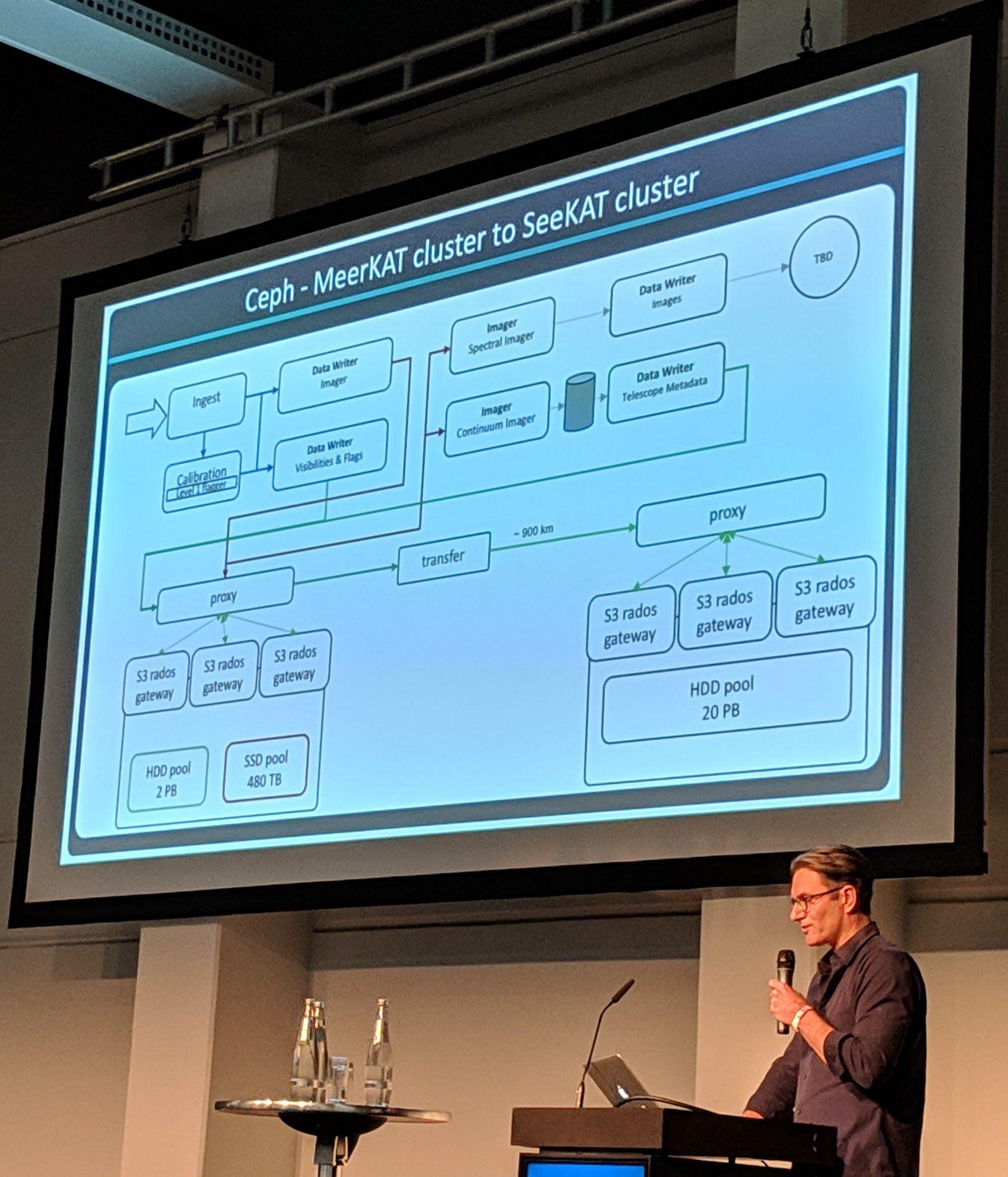
Ceph Day Berlin 2018 - Ceph implementations for the MeerKAT radio telescope, Bennett SARAO, SKA Africa - 'Ceph - MeerKAT cluster to SeeKAT cluster'
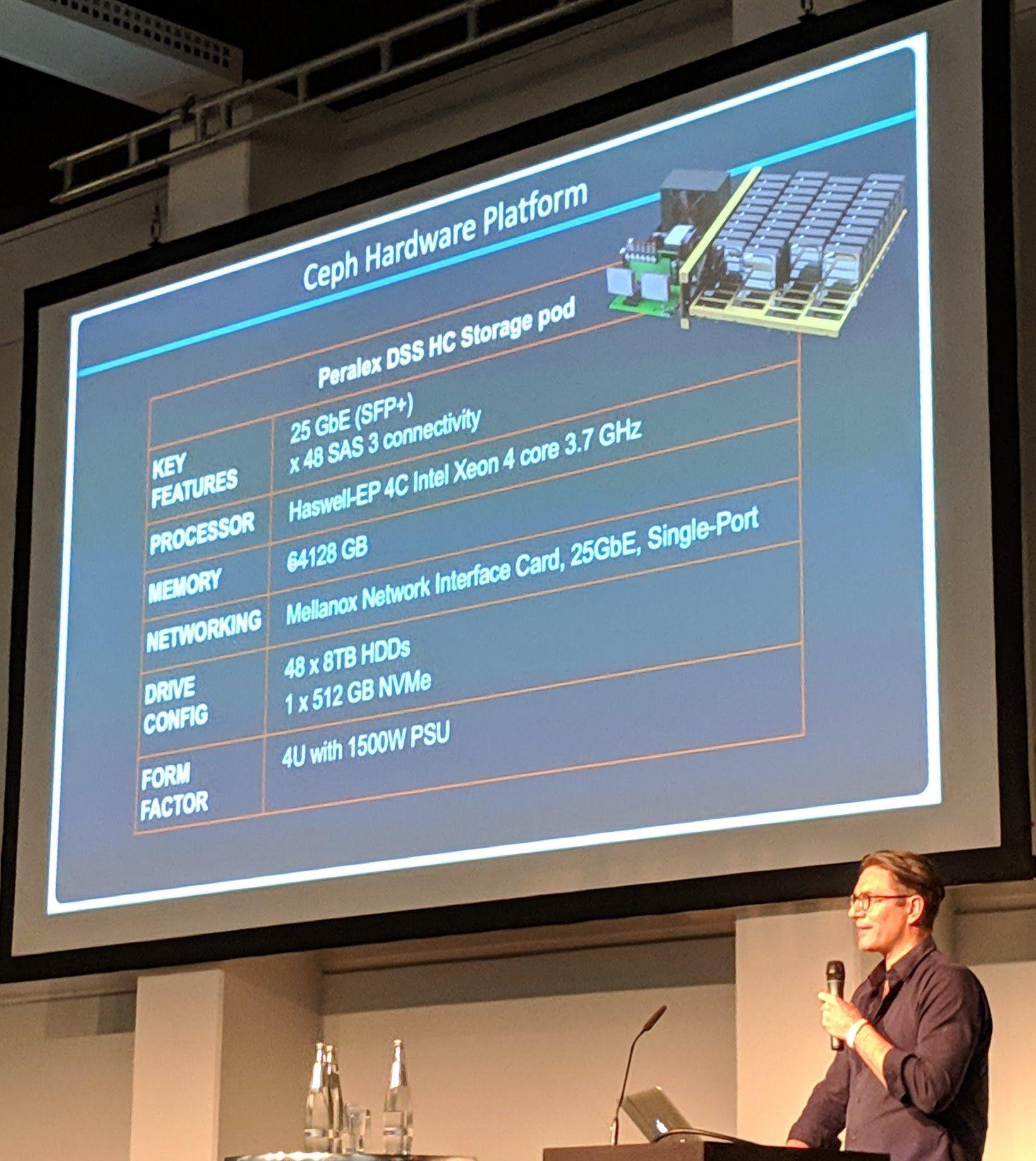
Ceph Day Berlin 2018 - Ceph implementations for the MeerKAT radio telescope, Bennett SARAO, SKA Africa - 'Ceph Hardware Platform'
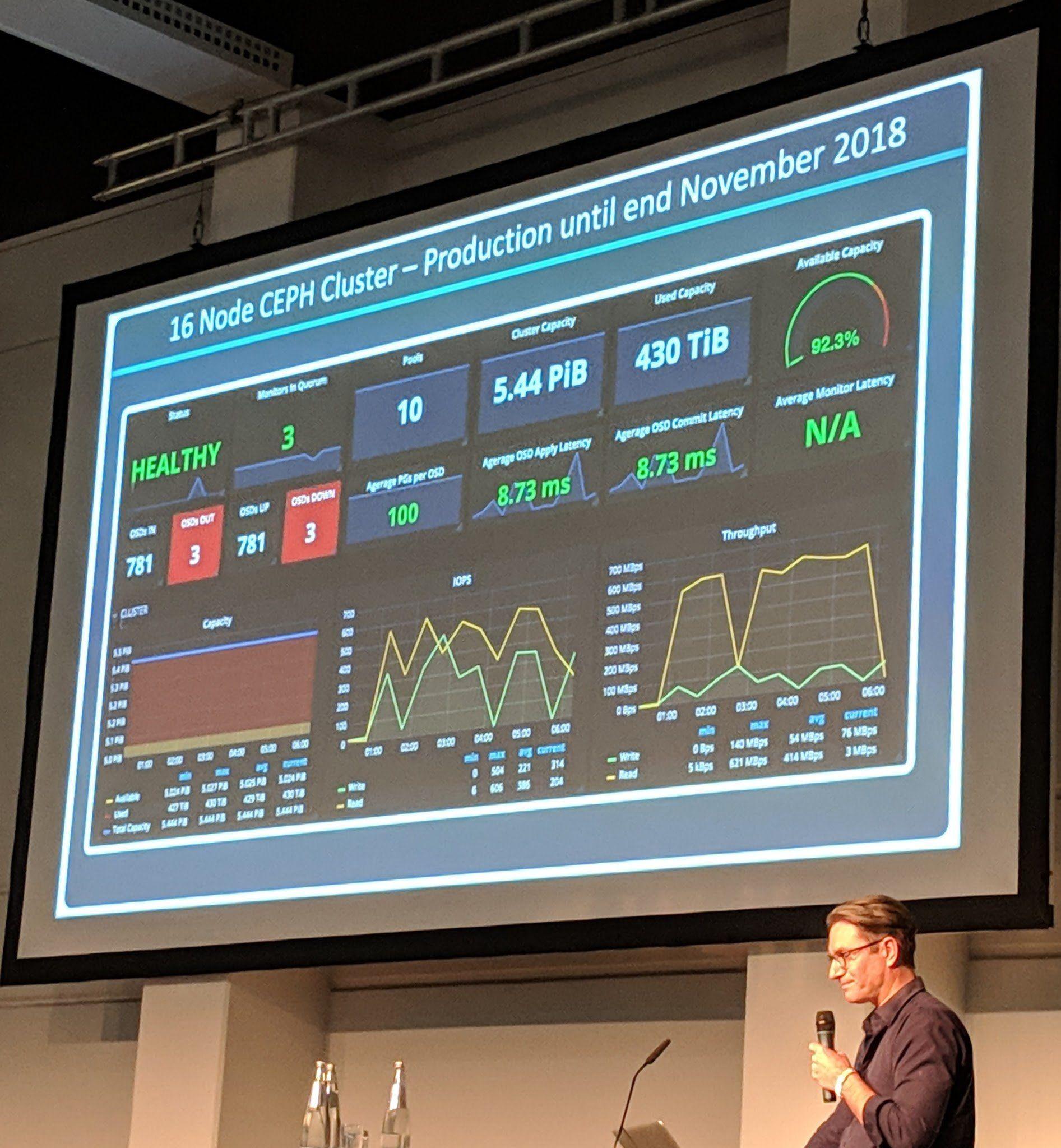
Ceph Day Berlin 2018 - Ceph implementations for the MeerKAT radio telescope, Bennett SARAO, SKA Africa - '16 Node Ceph Cluster - Production until end November 2018'
Interesting insights were given in the talk in how Ceph is used for such amounts from data for scientific research.
Disk health prediction and resource allocation for Ceph by using machine learning, Jeremy Wei, Prophetstor

Ceph Day Berlin 2018 - Disk health prediction and resource allocation for Ceph by using machine learning, Jeremy Wei, Prophetstor - 'Major Stability problem: Ceph Cluster'

Ceph Day Berlin 2018 - Disk health prediction and resource allocation for Ceph by using machine learning, Jeremy Wei, Prophetstor - 'Ceph DiskPrediction Plugin'
The disk health prediction is/will be merged into Ceph Mimic to allow for smarter data placement and/or preemptive movement of data before a disk fails. There will also be a mode for cloud providers to read the health of used cloud provider storage volume(s) and to act accordingly before there would be a failure on the cloud provider site in point of performance and/or latency hits.
Prophetstor will offer a commercial edition which has further support for even better detection and especially interesting anomaly detection for disks.
NOTE
Alameda is the open source project for such resource predictions and failure detection. A pull request is open at the Rook.io project for a design document.

Ceph Day Berlin 2018 - Disk health prediction and resource allocation for Ceph by using machine learning, Jeremy Wei, Prophetstor - 'The Brain of Resources Orchestrator for Kubernetes'
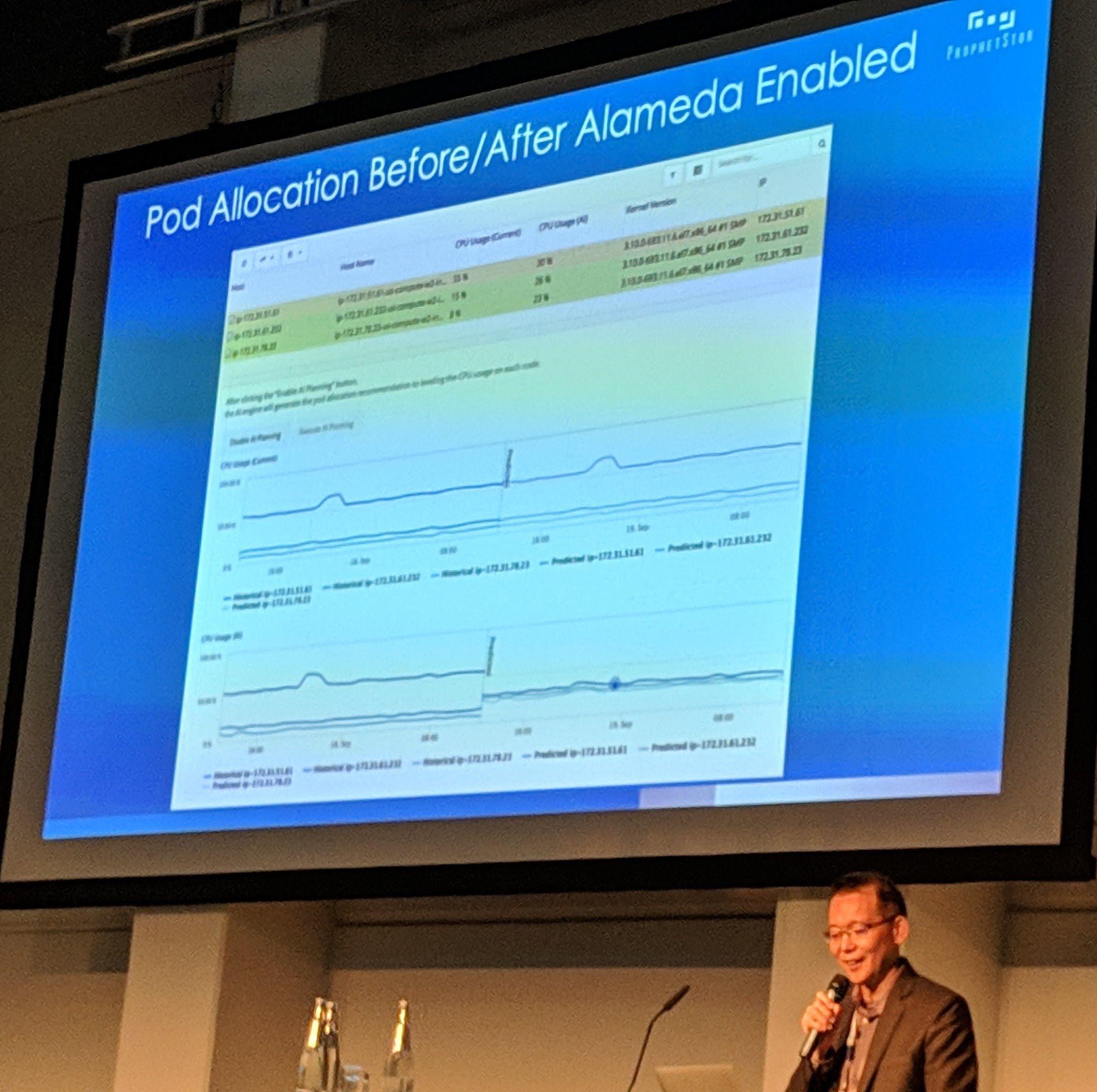
Ceph Day Berlin 2018 - Disk health prediction and resource allocation for Ceph by using machine learning, Jeremy Wei, Prophetstor - 'Pod Allocation Before/After Alameda Enabled'
Utilizing Kubernetes seems like the perfect way here as the workload in the Kubernetes cluster can be automatically adjusted/moved depending on the predicted information.
Mastering Ceph Operations: Upmap and the Mgr Balancer, Dan van der Ster, CERN

Ceph Day Berlin 2018 - Mastering Ceph Operations: Upmap and the Mgr Balancer, Dan van der Ster, CERN - 'CephFS Scale Testing'

Ceph Day Berlin 2018 - Mastering Ceph Operations: Upmap and the Mgr Balancer, Dan van der Ster, CERN - 'Do we really need CRUSH?'
In Luminous there is a new feature named upmap and a PG balancer.
upmap- Allows you to move PGs exactly where you want them.- PG Balancer - Can automatically balance PGs between servers.
The PG balancer allowed CERN to recover terrabytes of data because of how PGs were automaticallly rebalanced between OSDs.

Ceph Day Berlin 2018 - Mastering Ceph Operations: Upmap and the Mgr Balancer, Dan van der Ster, CERN - 'Turning on the balancer (luminous)'
(You need to restart the MGR (in Luminous) when this configuration has been set)

Ceph Day Berlin 2018 - Mastering Ceph Operations: Upmap and the Mgr Balancer, Dan van der Ster, CERN - 'A brief interlude...'

Ceph Day Berlin 2018 - Mastering Ceph Operations: Upmap and the Mgr Balancer, Dan van der Ster, CERN - 'Adding capacity with upmap'
upmap allows you to not worry about changes that would affect your PGs in point of being moved and/or rebalanced. Using upmap would basically allow you “pin”/map PGs to “stay” where they are or “force” them to somewhere else.
This is extremely useful if you change placement options which would normally require (for big amounts of data) weeks long of PG rebalancing. In such a case you would just upmap the PGs and they stay where they are when you made your placement changes.

Ceph Day Berlin 2018 - Mastering Ceph Operations: Upmap and the Mgr Balancer, Dan van der Ster, CERN - 'No leap of faith required'

Ceph Day Berlin 2018 - Mastering Ceph Operations: Upmap and the Mgr Balancer, Dan van der Ster, CERN - 'What's next for "upmap remapped"'
I think this would make a great core feature for Ceph. Though I think it would need to see improvements in user experience as it seems a bit complicated without as he said “their scripts” which generated most of their commands.
Deploying Ceph in Kubernetes with Rook, Sebastian Wagner, SUSE

Ceph Day Berlin 2018 - Deploying Ceph in Kubernetes with Rook, Sebastian Wagner, SUSE - Title Slide
It is good to see SUSE and RedHat talk about Rook.

Ceph Day Berlin 2018 - Deploying Ceph in Kubernetes with Rook, Sebastian Wagner, SUSE - 'Integration into Ceph'
A big point which is partly going to be “solved” by the MGR orchestration layer/module, that the orchestration “systems”, e.g., Rook, Ansible, DeepSEA and others, can simply integrate/implement the “bridge” to be able to be used as a orchestration “helper”. In the end, it shouldn’t matter if you want to run Ceph using Kubernetes, on bare metal using Ansible or DeepSEA and other possible environments. The Ceph MGR is currently, with the orchestration layer/module targeted to be the interface to do that.
If you want information about Rook, I would recommend to checkout the Rook project homepage: https://rook.io/.
Ceph management the easy and reliable way, Martin Verges, croit
Their approach boots the OS in an in-ram overlay filesystem for simple and easy updating. In addition to that, new servers register themselves by a “config” given to them by the PXE server.
When the PXE server is setup each node just needs to PXE boot, then one can select the nodes and disks on the nodes, and click the “Create” button in their webinterface to manage the node(s). ceph-volume will then be used to provision the disks for use as OSDs in Ceph.

Ceph Day Berlin 2018 - Ceph management the easy and reliable way, Martin Verges, croit - 'Is it Possible to Beat the Prices of Amazon Glacier with Ceph?'
There is a Vagrant demo available for croit in action, see GitHub croit/vagrant-demo.
5 reasons to use Arm-based micro-server architecture for Ceph Storage, Aaron Joue, Ambedded Technology

Ceph Day Berlin 2018 - 5 reasons to use Arm-based micro-server architecture for Ceph Storage, Aaron Joue, Ambedded Technology - 'Ceph is Scalable & No Single Point of Failure'
“Even with Ceph, hardware failure is painful.”
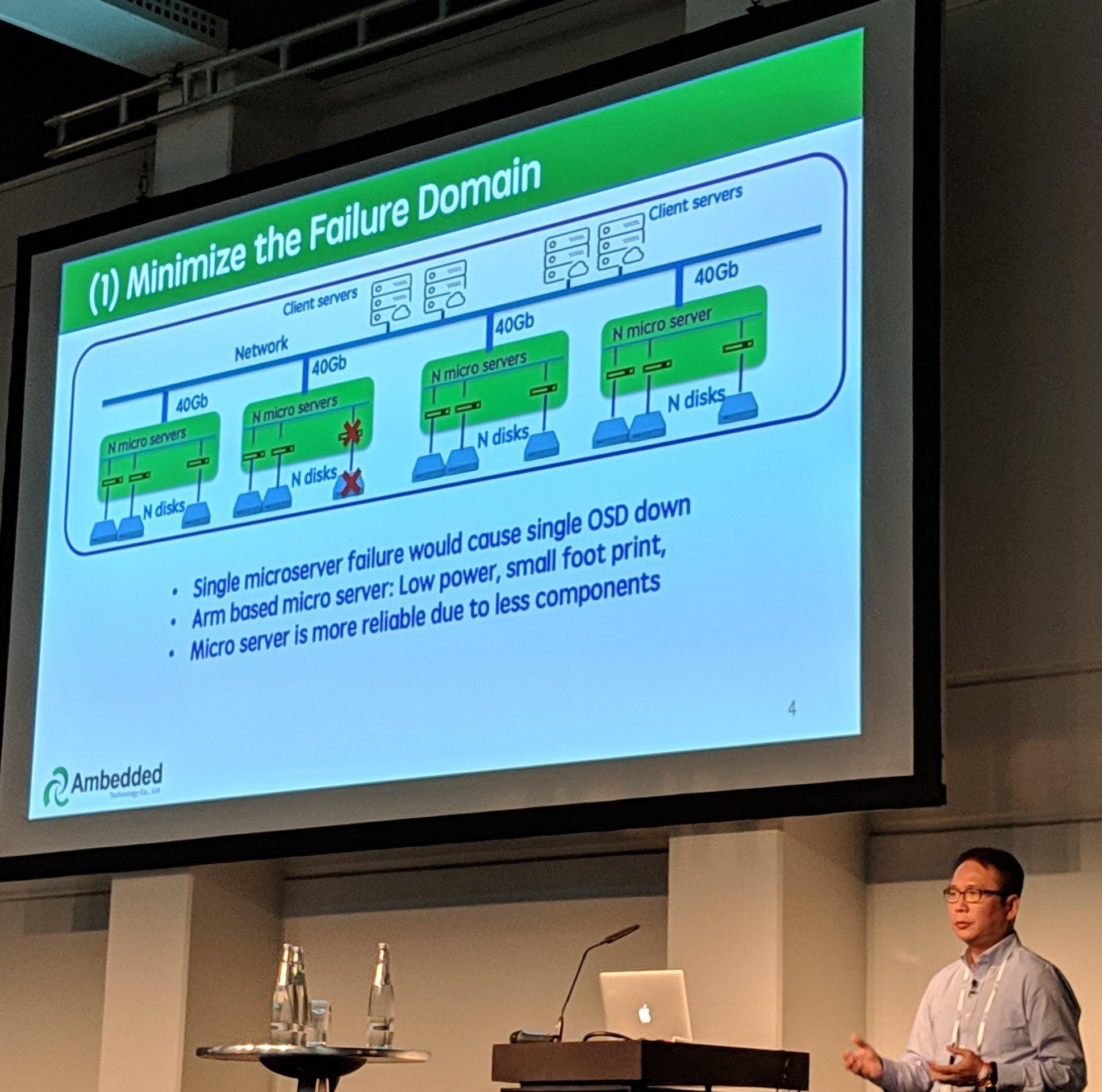
Ceph Day Berlin 2018 - 5 reasons to use Arm-based micro-server architecture for Ceph Storage, Aaron Joue, Ambedded Technology - '(1) Minimize the Failure Domain'
Using ARM based servers in a “certain way” allows to have the same performance at lower server and power costs.
Due to the servers using less power, you end up with a higher density than with most “normal” servers.

Ceph Day Berlin 2018 - 5 reasons to use Arm-based micro-server architecture for Ceph Storage, Aaron Joue, Ambedded Technology - 'Arm-based Micro-Server Architecture'
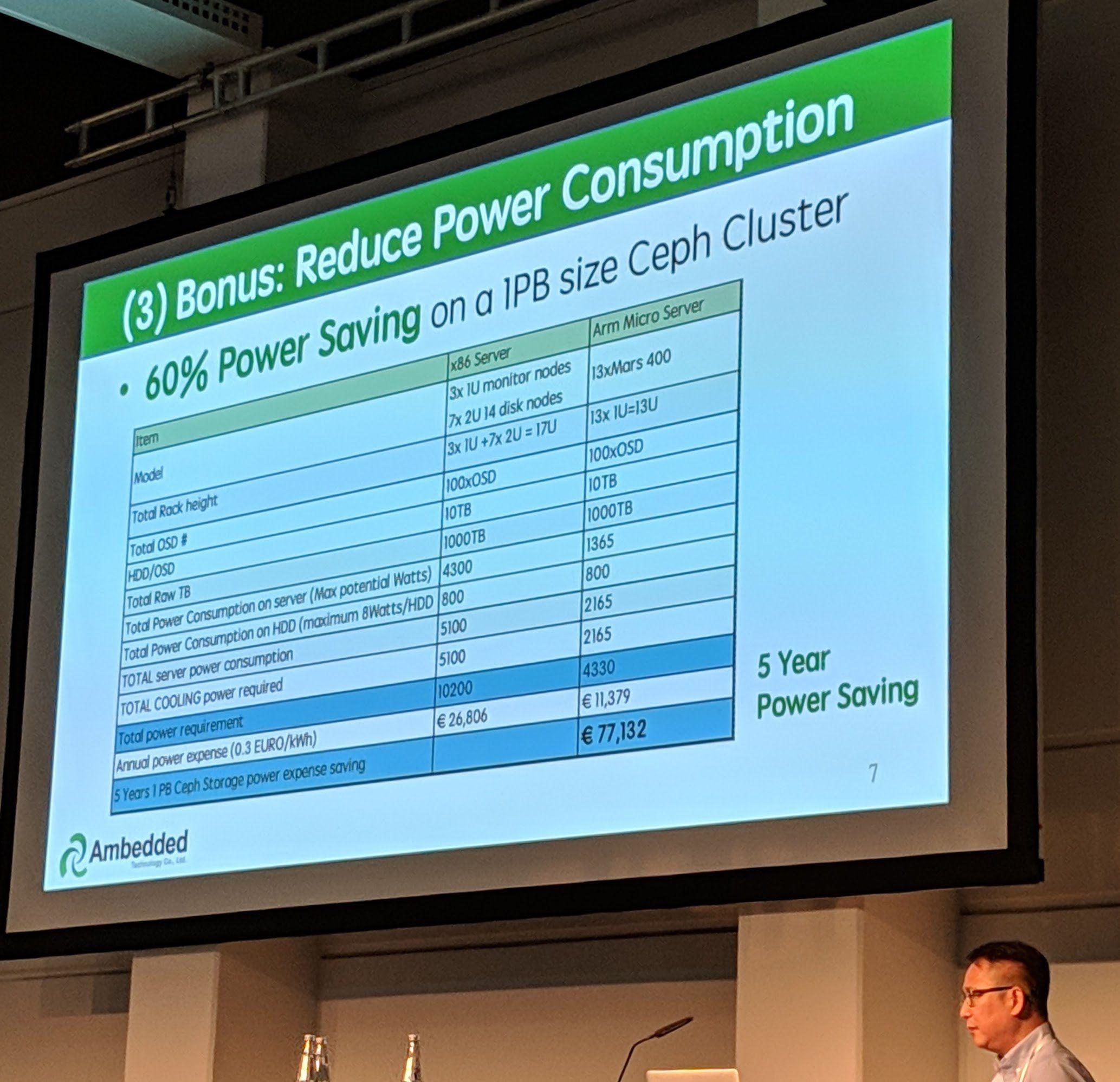
Ceph Day Berlin 2018 - 5 reasons to use Arm-based micro-server architecture for Ceph Storage, Aaron Joue, Ambedded Technology - '(3) Bonus: Reduce Power Consumprtion'

Ceph Day Berlin 2018 - 5 reasons to use Arm-based micro-server architecture for Ceph Storage, Aaron Joue, Ambedded Technology - 'Object Store Performance'
It is good to see performance benchmarks for Arm64 servers.
Practical CephFS with NFS today using OpenStack Manila, Tom Barron, Red Hat
NOTE
As this isn’t really a topic which falls into my interest area. I’d recommend to checkout the full slides of the talk on the SlideShare. Now have a few pictures without too much comments from my side:
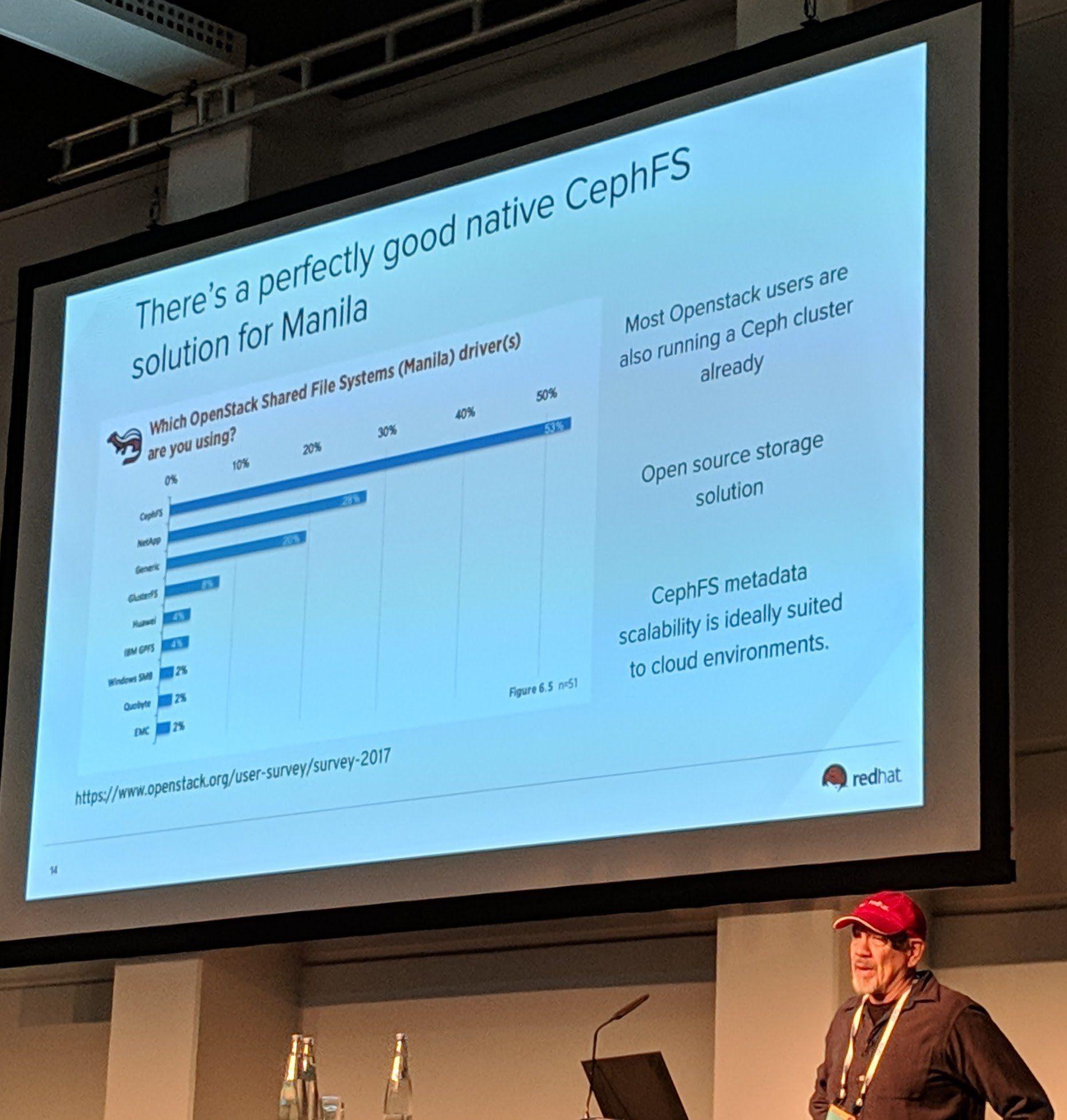
Ceph Day Berlin 2018 - Practical CephFS with NFS today using OpenStack Manila, Tom Barron, Red Hat - 'There's a perfectly good native CephFS solution for Manila'

Ceph Day Berlin 2018 - Practical CephFS with NFS today using OpenStack Manila, Tom Barron, Red Hat - 'Why NFS Ganesha?'

Ceph Day Berlin 2018 - Practical CephFS with NFS today using OpenStack Manila, Tom Barron, Red Hat - 'CephFS NFS driver deployment with TripleO'

Ceph Day Berlin 2018 - Practical CephFS with NFS today using OpenStack Manila, Tom Barron, Red Hat - 'Current CephFS NFS Driver'
Software mentioned in the presentation slides linked here for your convenience:
Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC

Ceph Day Berlin 2018 - Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC - 'Ceph on the Brain!'

Ceph Day Berlin 2018 - Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC - 'JULIA pilot system'
“Hot hardware when it was 2016”
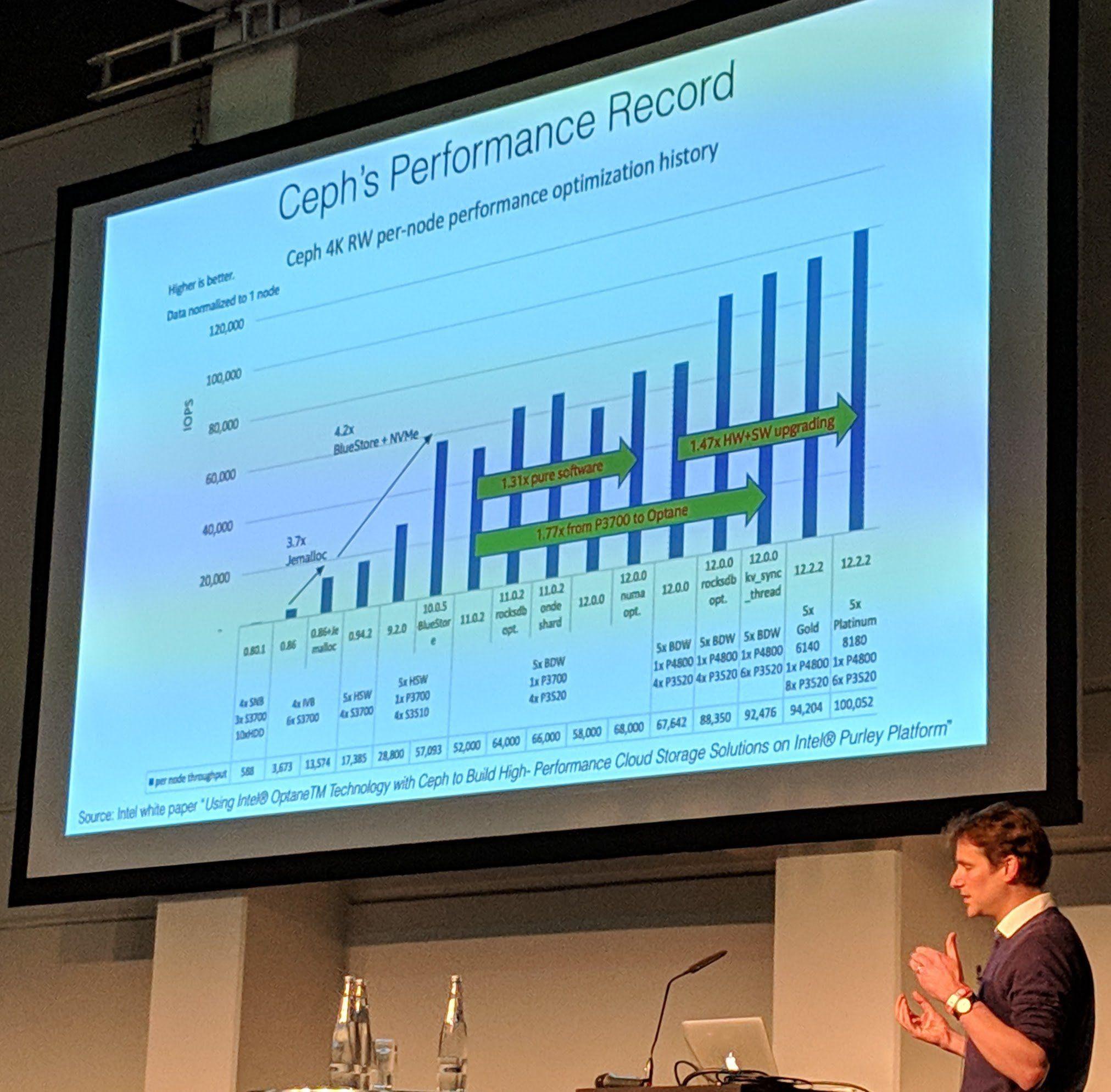
Ceph Day Berlin 2018 - Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC - 'Ceph's Performance Record'

Ceph Day Berlin 2018 - Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC - 'JULIA Cluster Fabric'
It is amazing to see that they reach around 5GBits on bluestore instead of mere 400-500 Mbit/s on filestore.
Interestingly they had immense losses in performance (from around 16 GBit/s to 4-5 Gbit/s) when they tried using LVM for the disks instead of direct partitions.
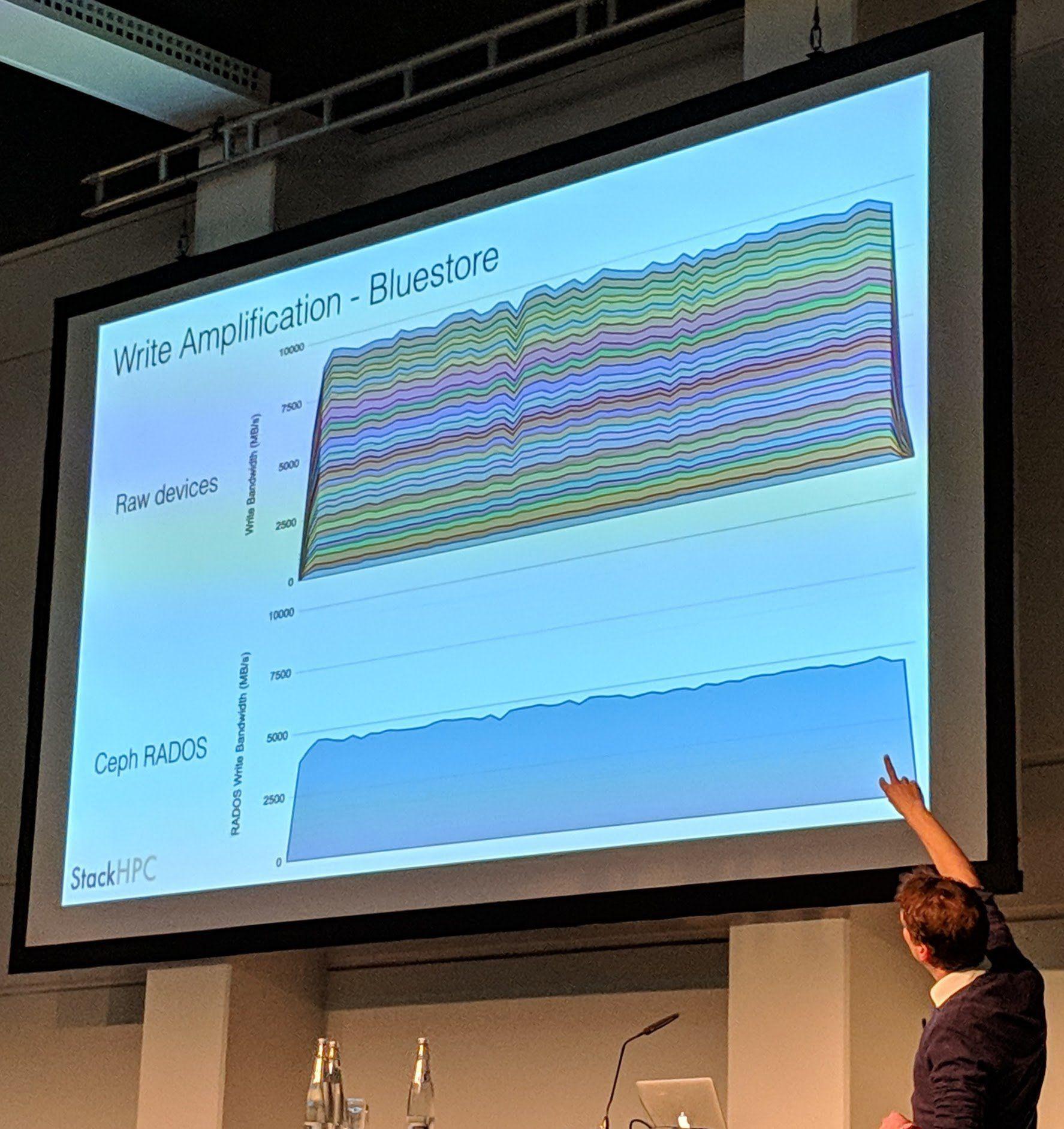
Ceph Day Berlin 2018 - Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC - 'Write Amplification - Bluestore'

Ceph Day Berlin 2018 - Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC - 'Spectre/Meltdown Mitigations'
Those loses of performance because of Spectre/Meltdown Mittigations… 15.5% I/O performance loss is huge in “any” Ceph environment. Not only looking at Ceph, for any application such a loss of performance is problem.

Ceph Day Berlin 2018 - Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC - 'Burst Buffer Workflows'

Ceph Day Berlin 2018 - Ceph on the Brain: A Year with the Human Brain Project, Stig Telfer, StackHPC - 'New Developments in Ceph-RDMA'
Into the cold: Object Storage in SWITCHengines, Simon Leinen, SWITCH

Ceph Day Berlin 2018 - Into the cold: Object Storage in SWITCHengines, Simon Leinen, SWITCH - 'Users Discover Object Storage: SWITCHtube'
“Like YouTube but without ads” most likely only for educational videos.
They use object storage not only for “cat pictures/videos and etc” but also for research data and everything else.
Keystone is “Denial of Service"d when it is not tweaked to “perfection” to handle many requests, causing increase in latency for every request to the object storage.
It is a challenge to (cost efficiently) save data for long-term.

Ceph Day Berlin 2018 - Into the cold: Object Storage in SWITCHengines, Simon Leinen, SWITCH - 'Customer Requirements/Expectations'

Ceph Day Berlin 2018 - Into the cold: Object Storage in SWITCHengines, Simon Leinen, SWITCH - 'Cost/Performance'
Using (aggressive) erasure coded for long-term storage sounds reasonable as long as the SLAs are correctly communicated and able to be kept with the chosen erasure coded configuration.
(As long as the aggressive erasure coded profiles don’t attack you while administrating the Ceph cluster)

Ceph Day Berlin 2018 - Into the cold: Object Storage in SWITCHengines, Simon Leinen, SWITCH - '"Moonshot" challenge for Ceph (or other SDS)'
Q&A

Ceph Day Berlin 2018 - Q&A Session - Speakers on stage
Cool to see all speakers that were still there, answering questions of the attendees.
Networking Reception

Ceph Day Berlin 2018 - Networking Reception
Free beer! After a whole day of talks about Ceph and talking to people about Rook, we were happy and exhausted.
I hope to see most Ceph Day attendees at one of the next Ceph Day.
Summary
The Ceph foundation is an awesome step forward for Ceph and projects using Ceph like Rook!
It was cool meeting Sage Weil and Sebastian Wagner in person instead of just through Rook meeting calls. The talks were interesting, though in general for me some were more interesting than others, but it was the perfect mix of topics.
Have Fun!