
Table of Contents
NOTE All credit for the slides in the pictures goes to their creators!
NOTE If you are in one of these pictures and want it removed, please contact me by email (see about/imprint page).
Thanks!
A huge thanks goes out to Rook and Quantum Corporation for helping me with my trip and the conference! Checkout their Twitter @rook_io and @QuantumCorp.
Day #0
NOTE If you don’t want to read about my flight and stay, skip to Day #1.
TL;DR First flight in a “long” time and alone, nervous as hell.

KubeCon: Flight - Boarding the plane to KubeCon
“Started from STR (Stuttgart) now we’re in the sky.” Totally not a “rip off” of a songtext by Drake

KubeCon: Flight - Look out of airplane window
I had a pit stop in Atlanta, and then flew to Austin. The flight to Austin was a bit rough because it just started raining when the airplane departed. After a total of about 12 hours, I finally arrived in Austin in the hotel. Pretty exhausted, but ready for KubeCon! Saying it here already, I was not really jet lagged, but I heard that flying back will definitely jet lag me. But well, I will enjoy my days off after KubeCon to “cure” my jet lag and get ready for work again.
Keynotes and Talks Recordings YouTube Playlist
KubeCon has published all keynotes and talks as a nice YouTube playlist, you can check it out here: KubeCon + CloudNativeCon 2017 - Austin - YouTube.
Day #1
INFO
The quality of the photos in this post varies pretty hard. This is caused by me using a smartphone camera to take the photos.
I was pretty lucky to be there early, as I got my badge instantly. Others hadn’t that much luck later on and had to wait a good time.
Rook Team + Booth
NOTE
If you don’t want to know about the Rook team + community photos and the booth, skip to Day #1 - Morning Keynotes.
INFO
These images were mostly taken on friday, the third day of KubeCon.
I was welcomed at the Rook both with swag from the Rook team for Rook. I also got the awesome green Rook birthday shirt, check it out on Amazon, part of the Rook team and I wear it in the photos below.
Me with Rook swag
 |  |
Please note the image was actually a photo sphere, that is why it looks a bit “bugged”.

KubeCon: Rook booth Shot #2
Morning Keynotes

KubeCon: Keynote Day #1 Shot #1
A Community of Builders: CloudNativeCon Opening Keynote - Dan Kohn, Executive Director, Cloud Native Computing Foundation
There are over 4k+ people at the KubeCon. That is more than the last three events together. Even in point of terror attacks, we, the community/people “continue developing, building” our awesome projects. Additionally to all the awesome tracks there has been the first Serverless track at KubeCon. “Kubernetes is the Linux of the cloud”, it is Open Source Infrastructure that works anywhere. It is amazing to see the statistics of the Kubernetes and other related projects at devstats.k8s.io. Containers have pushed the boundaries allowing us for quick/fast delivery of applications. Today there are hundreds of Meetups around the world about Kubernetes and overall cloud native. There are free EdX courses by CNCF/Kubernetes available. Also the Certified Kubernetes Administrator “programm has over 600 people already registered.
CNCF Project Updates - Michelle Noorali, Senior Software Engineer, Microsoft Azure
A goal of the CNCF now is to reach commercial sustainability with the projects. The CNCF member count is “sky rocketing” and currently at over 150+ members. This helps the community through funds to support projects. Stats about the CNCF:
- 25 certified Kubernetes service providers (example cloud providers for an easy Kubernetes)
- 42 certified Kubernetes Partners
- 14 projects currently hosted
- A lot of CNCF scholar ships in Texas, Austin and around the world
The next KubeCon will be held in Copenhagen on May 2018, additionally there will be a KubeCon in China, Shanghai in Novemeber 2018 to “compensate” the increasing usage in the Asian market of CNCF projects.
Kubernetes was the first project donated to the CNCF. This is especially awesome to look at how cloud native Kubernetes is. It allows scaling, allow for cross cloud deployments and much more.
Container Storage Interface (short CSI) allows simple and no vendor lockin storage integration for containers in general but will also soon be coming to Kubernetes.
CoreDNS v1.0 released, in Kubernetes v1.9.x it will be available as a replacement for kube-dns.
Containerd (orignally built by Docker) has released version 1.0.0, there is also a (Kubernetes) Container Runtime Interface (short CRI) implementation available.
CoreOS’ rkt is security-minded and also CRI compatible. CoreOS “created” (and is currently maintaining) Container Network Interface (short CNI). CNI makes the network layer pluggable for not only containers.
If you haven’t know yet, “everyone” uses CNI, Kubernetes, Docker, rkt, CRI-O, etc).
Observability:
- Prometheus (with PromQL) was the second project accepted into CNCF. With the Prometheus
v2.0release, they reduced the IO by 100x with the new storage engine used. Additionally there will PromCon’s next year again. - Fluentd (solves the logging pipeline problem; aggregation, filter, etc) version
v1.0has been released. This release contains a new Fluentd forward protocolv1, improved Prometheus support/metrics. Fluentd is more and more a full ecosystem, to further build on that they have released fluent-bit which allows forwarding of data/logs to Fluentd (it feels a bit like Elastic Beats).
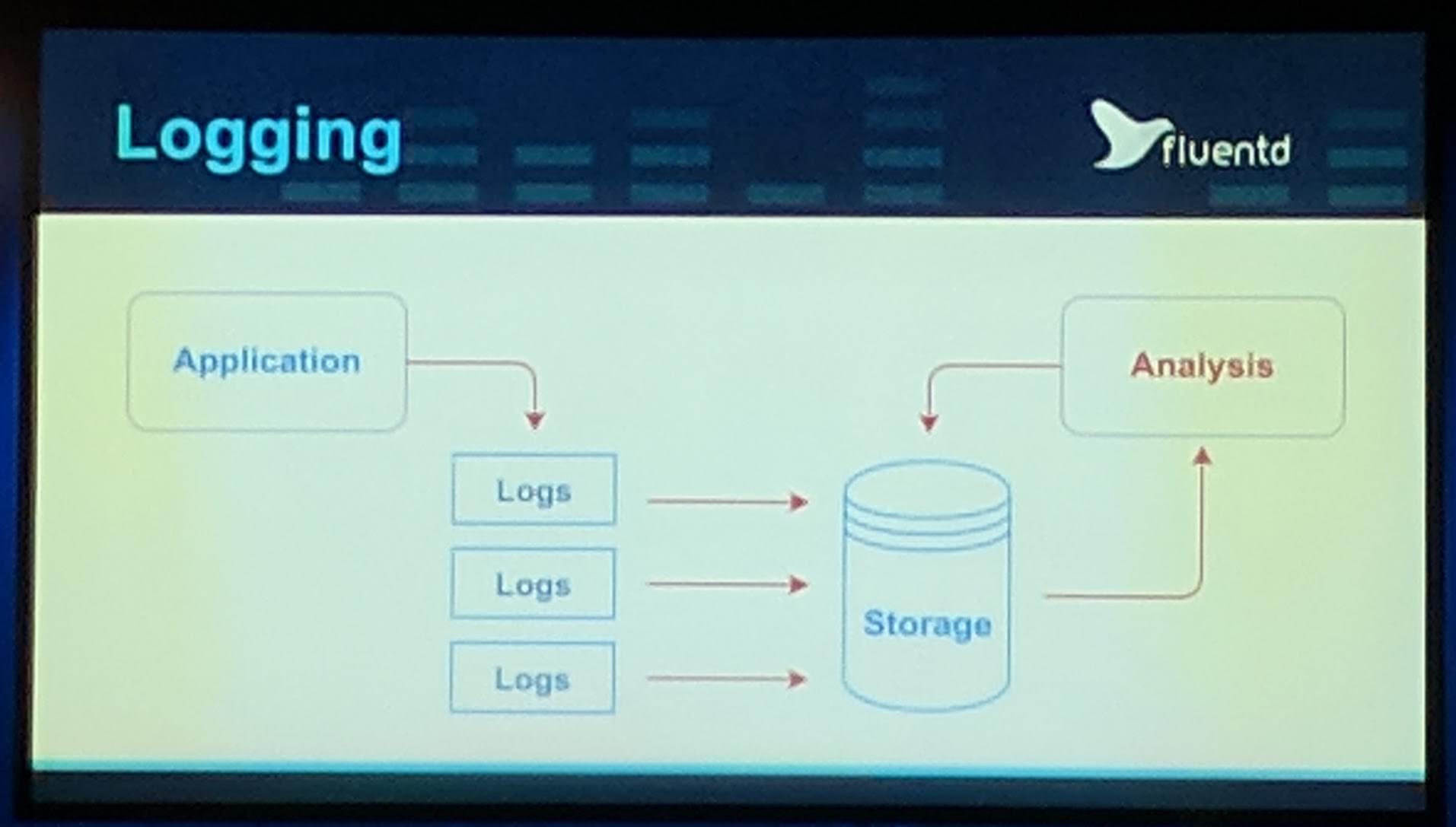
Fluentd logging flow
- OpenTracing is a vendor neutral standard for distributed tracing. They have released OpenTracoing implementations for 4 new API languages.
- Jaeger implements the OpenTracing standard and is working on better integration into other CNCF projects.
Relibaility:
- Linkerd allows the creation of a service mesh. Linkerd has attracted many new big company users. They also announced a “new” project Conduit.io it is also a service mesh but very lightweight and currently only for gRPC traffic.
- Envoy is a service proxy. The integration into Kubernetes is done through an Ingress controller which can be found here GitHub heptio/contour.
- gRPC allowed Google to improve secutiry and relibaility for their services. They are currently working on creating implementations for more languages.
Security:
- TUF: Software Update Specifications. A goal is to retain as much security as possible (for example used for Internet of Things devices). They announced that Notary, which implements the TUF specification, has released version
v0.6.0.
Accelerating the Digital Transformation - Imad Sousou, VP, Software Services Group & GM, OpenSource Technology Center, Intel Corporation
There is a new container runtime by Intel called Kata containers (“Kata” means “Trust” in Greek). It is especially taking a look at “isolation” of containers. Containers “normally” have less isolation due to a) more applications running on one host/node and b) the containers are most of the time just separated by Kernel CGroups. It is kinda always a “Speed OR Security” (Container VS VMs). Using Intel(c) Clear Containers and Hyper’s runV allow hardware accelerated containers. Kata containers are compliant to the CRI specification. Additionally good for the Kata container project is that a lot of contributors are not only from Intel(c) but also from other companies (“independent”). If you are interested get involved in the project!
Also there was a mention of the AlibabaCloud about their new X-Dragon bare metal cloud servers that can serve up to 4.5 Million pps. AlibabaCloud works on (better) integration for their cloud platform to Kubernetes
Cloud Native CD: Spinnaker and the Culture Behind the Tech - Dianne Marsh, Director of Engineering, Netflix

KubeCon: Keynote Netflix Shot #1
Before I begin, this keynote/presentation/talk was one of the best presentations of KubeCon for me. It had so much to learn/“takeaway” from.
The culture (of a company) impacts Tools and Technologies. At Netflix employees are encouraged to work with “Freedom & Responsibility” and “Share information openly, broadly, and deliberately”.
The second point about sharing, code can be taken as an example for that. Employees/Teams should be able to openly share their code. This again can be seen differently, from being broadly open by open sourcing code for the public (GitHub, GitLab.com, etc) or at least being able to share code in the company’s code management system.
Back to Netflix, there was a lot of pressure on the Spinnaker and Edge Center team. Every team solved their “own” problems fast, but didn’t “catch up” with each other.
To have the “Courage and Selflessness” especially as an engineer, saying that he isn’t able to keep up with the other project takes some “balls” to do.
Spinnaker is a continous integration and deployment tool, to directly note it supports only Active<->Active application deployments.
In 2015 Netflix released Spinnaker as an open source project. Open Source “always” does good to a project, as today it supports multiple cloud providers to due the pluggable and multi cloud provider architecture from the begining on.
To go into “open sourucing an internal project” a bit further, Spinnaker is a good example of how open sourcing a project can allow a company to gain from it. Through the community the project gained features like support for more cloud providers and also overall find issues “better” due to more users of the project.
A point that can’t be truer is “You better understand your service than anybody else”. Who doesn’t know “every” specific detail of their code they have written and I’m not talking about undocumented features, more of just the structure that someone could “ask you in your sleep” and get an instant response from you.
“Guardrails, not Gates” <- THIS, this is kinda mind blowing when you think about it. “Engineers should decide when to deploy”, “Am I ready to deploy without a manual step?” these are questions you should ask yourself before going live. To get back to the first “THIS” again, you shouldn’t make a gate someone can “simply” climb over. You should make a working guardrail to guide people to the correct thing.

KubeCon: Keynote Netflix Shot #2
A criticality for business’ deployments is to more and more have “Increasing interest in delegation(bility)”. Instead of what I can tell about myself to, do everything myself, know I can delegate something and not because I was told but because I want to.
An overall summary for some of these points is “Think carefully about the tools you chose, are you fighting the culture with it?”. You should always take the culture of your company/environment in to account when choosing a tool/technology. For example, “does it make sense to use Kubernetes?” “We already have a working agile platform to deploy from. Why switch to Kubernetes?”.
As I wrote in the beginning for this keynote, it was one of the best keynote talks for me. I hope this can be read from writing.
Cloud Native at AWS - Adrian Cockcroft, Vice President Cloud Architecture Strategy, Amazon Web Services

AWS works to integrate cloud native components into ECS
Amazon Web Services is looking forward to “Grow Communities, Improve Code, Increase Contributions”. A Kubernetes related point is that the scalability testing will be moved to AWS soon. About AWS Network, they have it fully integrated into CNI and the changes are already in the upstream. Just use CNI and you “get” AWS networking There is/will be some kind of bare metal servers available on AWS. AWS Fargate takes away “everything” around Kubernetes. It is kind of like SaaS for Kubernetes where you just provide the applications. This is especially good for when you don’t want to run the instances below your Kubernetes. Fargate is a bit like AWS’s own GKE. They are building “An Open Source Kubernetes Experience”, where you simply bring your “manifests” and are good to go. The “Open Source Kubernetes Experience” from AWS will also try to integrate most AWS services “natively” into the clusters. If you want to dig deeper with security on AWS, there will be IAM authentication with Heptio and additionally Kube2IAM, which adds IAM to Pods (ServiceAccount), but this is currently work in progress.
Talks
The True Costs of Running Cloud Native Infrastructure [B] - Dmytro Dyachuk, Pax Automa
NOTE
I haven’t gotten to the first part of the talk.
Still the part I saw was pretty interesting. Overall most costs are for compute power (not “only” energy power, especially CPU), storage second and third especially in case of colocation people/staff maintaining the servers. Storage is second because it depends on how many IOPS you want/need. If you want good good enough hardware to deliver the IOPS you need and want it may even come in first. This shouldn’t be overlooked during your planning.
Aggregated values of how often the workload(s) got scaled up’n’down is a “must” to take the future into account and not run out of resources mid-way of a new deployment. Through the dynamic of clouds (providers) there is no issue for resources, as they can be added on the fly, but still it is not that easily with 1:1 deployments (looking at different cloud regions, resources may not available the same between regions). Over time the amount of reserved resources should be increased, this potentially also applies to limits for deployed workloads. Increasing the reserved resources and limits on applications over time allows to make sure that for reserved at least always what is needed is available and for limits on workloads they allow for better control of what is needed for scaling up further. This allows to make sure that for existing and new demand there are enough resources available for use. Over provisioned resources can be used for workloads as an example batch jobs or any workload that can be scaled down without impact to customers.
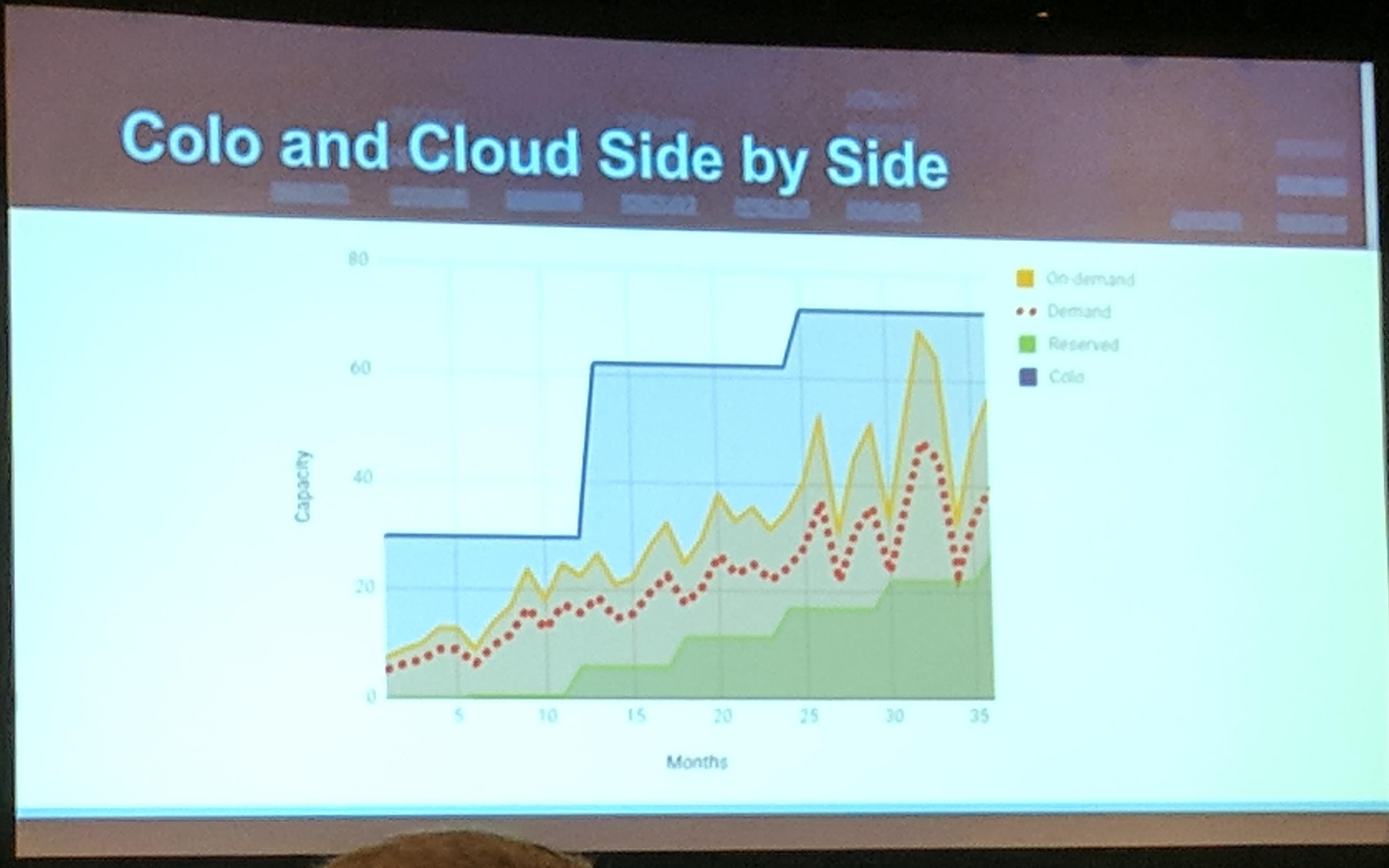
KubeCon Talk: Colocation, AWS side by side
Taking a closer look at colocation, there are “always” more resources available as needed and the costs with that only increase when more is needed (not taking upgrades and hardware End Of Life into account here). Through this money can be saved, but to be able to do this in a good way the right analytical values need to be taken into calculation.

KubeCon Talk: Colocation Provisioning workload diagram
Additionally to note here is that at one point a cloud provider (in the talk it was AWS as an example), colocation wins as the costs “stay” on a continual level and only increase when new/more resources are needed.
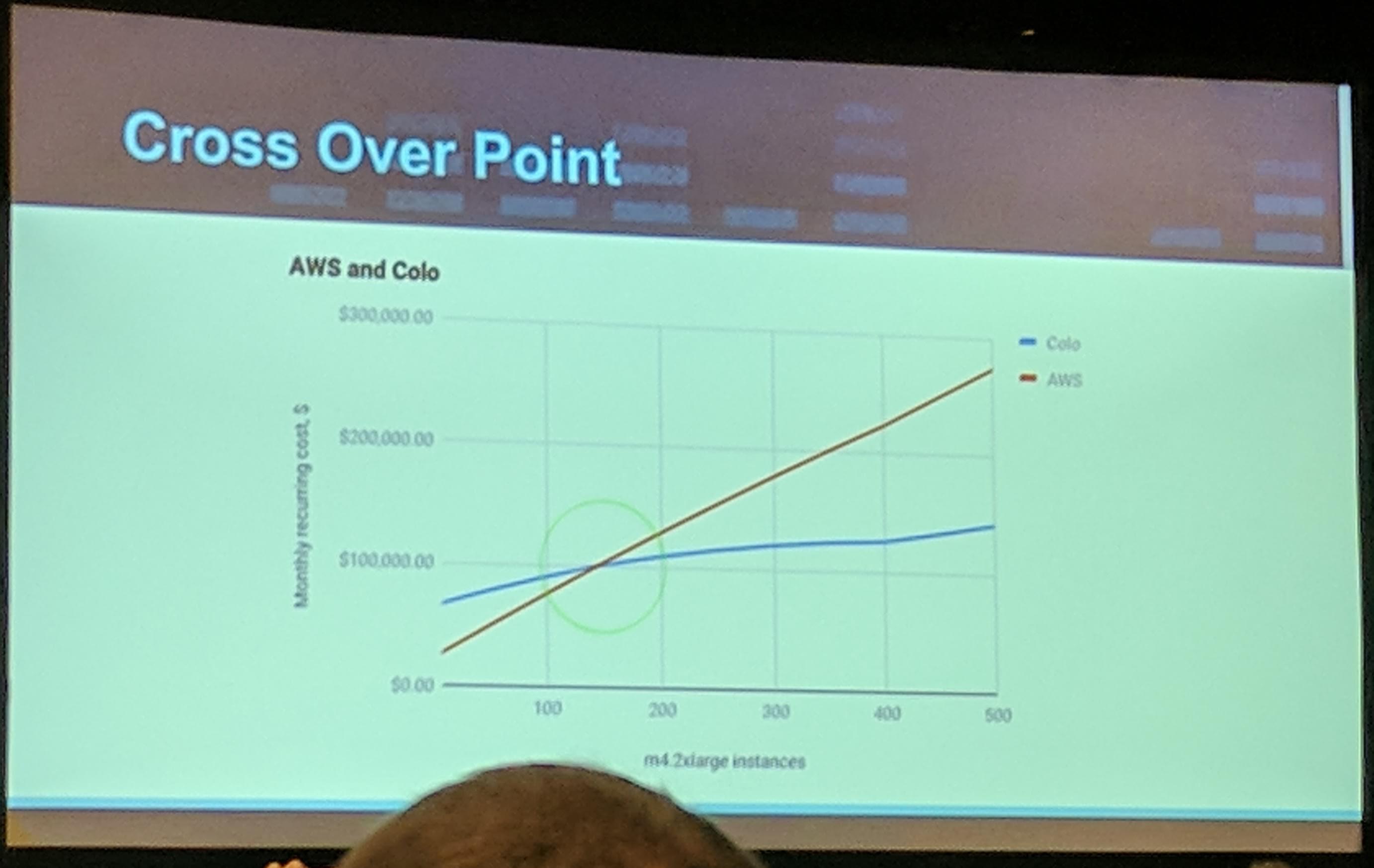
KubeCon Talk: Colocation vs AWS cost Cross over point
It really depends on the changes of the workload and what the application(s) needs for dynamic scaling. Examples:
- CPU heavy workload may be better run on AWS as CPU is cheaper to up’n’down scale quickly on demandm, where colocation/bare metal could be more expensive.
- Storage heavy workload may better of with colocation may be cheaper due to the “one time” cost for the storage servers.
Additionally it may also only stays cheap(er) at a certain scale of the total workloads with colocation. If you only have a huge spike of load sometimes a cloud will be cheaper than colocation.
My takeaway is that you should always plan for at least one cloud provider and colocation (bare metal).
CRI-O: All the Runtime Kubernetes Needs, and Nothing More - Mrunal Patel, Red Hat
CRI-O or Container Runtime Interface Open utilizes runC to create and run containers. CRI-O seems to allow an “init” system for the container process to be started that does the reaping of “detached” processes.
The integration into Kubernetes also seem to be simple and stable. The change to use CRI-O for Kubernetes passes over 300 tests for PRs in Kubernetes, without any changes to Kubernetes in “favor” of CRI-O.
As most container runtimes do, it utilizes CNI to configure the network of a container.
CRI-O looks like a pretty good alternative to Docker (and other runtimes) when running a Kubernetes environment.
Next steps for CRI-O will be to release version 1.9. The releases will be in hand with each Kubernetes versions and support the Kubernetes specific version too.
Their blog is available at: CRI-O Medium.
For OpenShift users it is also already planned to use CRI-O instead of Docker (which is currently the default).
It is full feature compatible to running Kubernetes with Docker. Log format is different to Docker’s format. Everything that directly consumes the logs needs to use the CRI-O format (like Kubernetes cluster addon Fluentd).
CRI-O is tied to Kubernetes (and will be tested with Kubernetes together too). When running something else than containers on Kubernetes, one should consider evaluating the available container runtimes to see which fits the workload.
A switch to CRI-O for 100% Kubernetes environments seems like a good step to do. Depending on how you update your Kubernetes, you may not have any additional steps (maybe even less) after a switch to CRI-O.
Building a Secure, Multi-Protocol and Multi-Tenant Cluster for Internet-Facing Services [A] - Bich Le, Platform9
Platform9 has a project named Decco that manages Namespaces and Network Policies in Kubernetes for them. They use CustomResourceDefinitions for that.

KubeCon Talk: Decco Traffic Management Slide
Additionally to network policies Decco has upcoming support to do authentication of traffic with Istio. The current authentication flows were shown for TCP and HTTP traffic.

KubeCon Talk: Traffic Flow TCP Slide

KubeCon Talk: Traffic Flow HTTP Slide
Looks like a pretty interesting project to manage multiple projects (and maybe even environments/stages) on top of a single Kubernetes cluster. THis seems like a good possibility for companies looking to regulate namespace creation and security around them.
Evening Keynotes
I haven’t been to many talks/presentations today due to many interesting discussions/chats with the Rook team and other awesome people at KubeCon.
Service Meshes and Observability - Ben Sigelman, LightStep
“A Service Mesh can help”! Nobody likes to write the same things over and over again. Through reduction of one big service into many (micro)services this can be achieved (depending on the type of service you are running). This thought goes into the direction that when you use smaller parts (microservices) for services, you can reuse them and scale them individual. But there remains one big problem for microservices. What can be done to help reduce the “Ahh which microservice is broken?” during on-call. A distributed tracing tool is a good “weapon” against that and to gain insight. OpenTracing can help to keep the difference between tracing formats between multiple languages small as it is a standard.
The big part of distributed tracing is having all information for a trace from the first service the traffic enters to every service with all the information required to debug “any” issues (be it performance, errors or exceptions). When the (micro)services are more complex this can be a big hassle to achieve, as services then sometimes have queues for requests, etc which makes tracing even harder to achieve and read during analysis.
Donuts as a Service (DaaS): “Scaling fast and running into performance issues”
Jaeger, a CNCF hosted project, allows you to view the traces in a detailed way, but you still need to have the whole data of every trace. Analyzing traces on a huge business level is harder the more concurrency of overall requests you are having. Currently there are tracing sidecars available for some protocols/applications already (for example nginx, Conduit).
BTW Examples involving Donuts are pretty nice.
Kubernetes: This Job is Too Hard: Building New Tools, Patterns and Paradigms to Democratize Distributed System Development - Brendan Burns, Distinguished Engineer, Microsoft
Enable people to build distributed applications.
A lot of tools/steps before deployment. Before you can think of your application you have to go throuh the “whole” process of what to use.
A problem with development would be that some values for example port 80 specified in the application, the Dockerfile and Kubernetes manifest makes it prone to errors when one change in these files has been forgotten.
First principle is to have a “Everything in one place” that contains information such as what is the port of the application. So that it only has to be changed in one location and not cause issues because it was only changed in one in later times. Second principle is “Build libraries, not platforms”. Meaning that instead of always building 100% specific to an application, write code that can be reused in form of libraries that is most of the time. Third is “Encourage sharing and re-use”. That built applications/libraries are shared with teams or even the open source community (GitHub, GitLab.com). I personally think that the second and third are especially connected with each other. Sharing a library allows to not write code over and over again, and lower the “risk” of building a “platform” instead of an application.
Takeaways:
- Why not unit test your configs too?
- Design your application in (pseudo) code.
- Make the application/code more approachable (example for new employees).
- As hopefully always, unit, style and other tests should be written and run.
When looking into which “item” you can map to the following:
- Standard Library -> ???
- Runtime -> Kubernetes
- Objects -> Containers
There is nothing “universal” for a “Standard Library”. This is where the Metaparticle project comes in. It allows for an application to contain instructions on how to build, push and deploy itself. Also functions for distritbuted sharding, locking and other important functionality which is normally written over and over again is included in Metaparticle. Additionally it tried to reduce gaps for the “problems” with knowledge of building distributed applications and as mentioned earlier code for “simple” distributed applications tasks (locking, sharding, etc) isn’t written over and over again.
Can 100 Million Developers Use Kubernetes? - Alexis Richardson, CEO, Weaveworks
The bot that colorizes black and white images, OpenFaaS (Functions as a Service) project played a huge role. When something (an application) could be “merged”/splitted (libraries), it will reduce the time needed to re-do a lot of work/code already done (multiple times).
A big point during the keynote was: “What are we building for?” -> For the future of today’s kids.
Community Awards
Congratulations to all the winners of the awards! Thank you for your contributions to the community!
Party
There was a marching band playing after the Keynotes in the sponsor showcase:

KubeCon: Party marching band
I only attended the party with Rook and SPIFFE, not the “official” KubeCon one. It was interesting to see Ignite Talks for the first time.
Day #2
Morning Keynotes

KubeCon: Keynote Day #2 Shot #1
KubeCon Opening Keynote - Project Update - Kelsey Hightower, Staff Developer Advocate, Google

KubeCon: Keynote Kelsey Hightower at it again
“Kubernetes changelog is boring” because Kubernetes is now on a level/maturity as a project on which you can build stuff on top of it!
Kelsey Hightower showed off voice controlled Kubernetes cluster creation on Google Cloud Platform.
If you need to create a ticket to deploy, you should stay with having separate clusters (and don’t work against the “culture”).
“No one cares”, to be exact developers, don’t want kubectl on their systems. They just want to develop their application(s)/project(s).
“Wanted is that when a code change is done, the dev gets a URL to where it is running (even better get metrics for it too)” like GitLab Auto DevOps style which allows to do exactly that automatically for you.
Config is “Implementation details”.
“Be in shame when you build your releases on a laptop” I can’t agree more on such a point.
A full workflow should be simply available for (every) application. This really goes into the direction of using something like GitLab Auto DevOps, which kind of takes care of the workflow and instantly sets you up with something working.
- Push -> Build -> Deploy to dev (with URL + Metrics available)
- Tag -> build -> Deploy to QA
“Visibility for users”, when users have the visibility they don’t have the need to get access/tools (kubectl), because they already know what is going on. Another point “Don’t rebuild the image between QA and Live” that I also just can agree to 100% in. There is a reason why you test something in QA and with containers you just move it to production/live because you know that image will work and do what we tested. This is a very interesting point for Emergencies, “Emergencies should allow to run without pupelines”. Depending on how you see it, this is kind of controversial. I’ll leave it at that.
Kubernetes Secret Superpower - Chen Goldberg & Anthony Yeh, Google
A large eco system has formed around Kubernetes.

KubeCon: Keynote Kubernetes' system layers
Kubernetes is ready for us, the community and companies to extend/build on, as in the previous Keynote written.
Kubernetes is build for chaos as a cloud native application should be able to handle. Because of Kubernetes “being built for chaos”, you can see Kubernetes as many reconcilation loops “all the time” to make sure chaos gets resolved.
Through techniques like CustomResourceDefinitions it is simple to build an “extension” for the Kubernetes API server.
But there are also other ways to build upon the Kubernetes Apiserver, which can be seen in the images below.
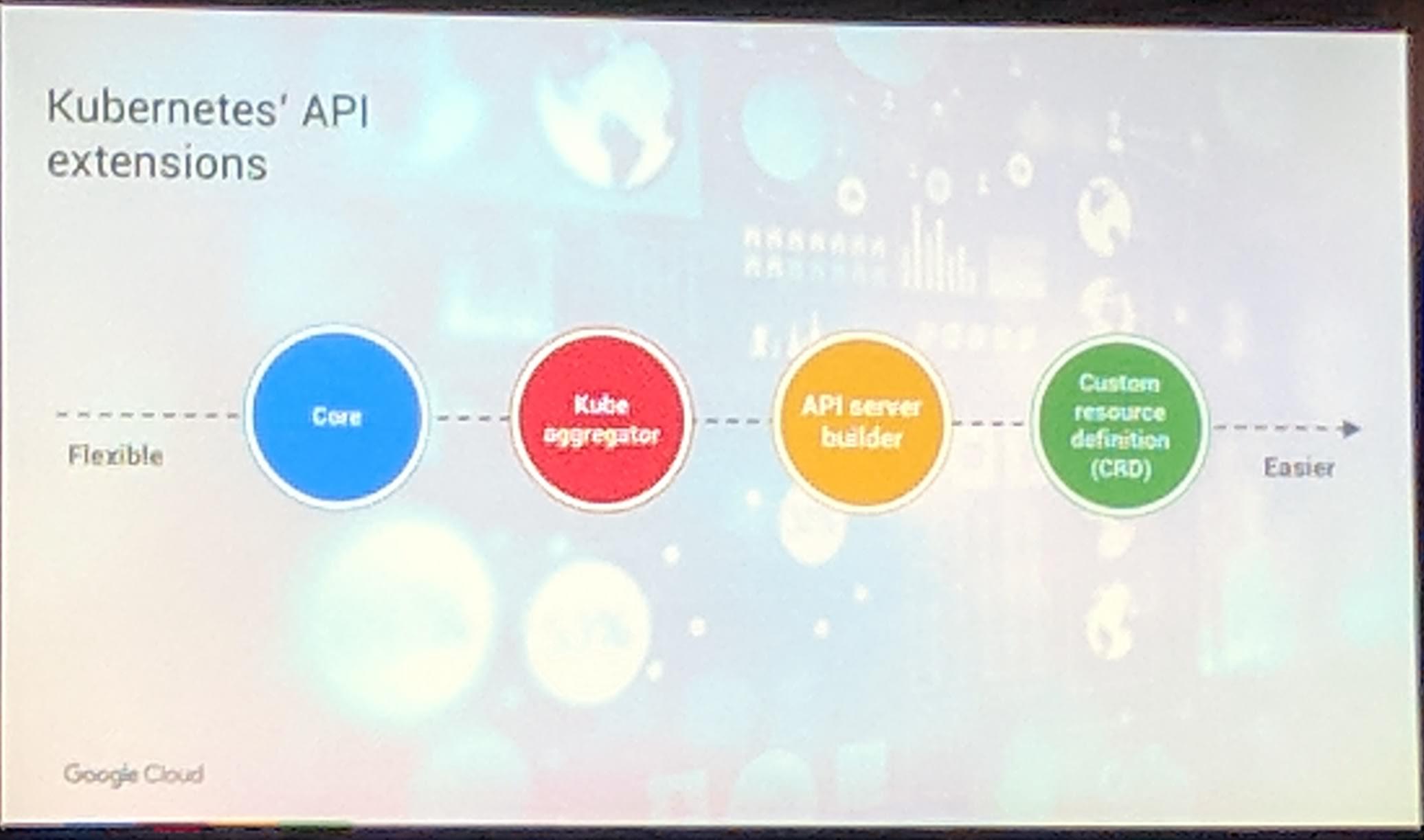
KubeCon: Keynote Kubernetes extension from flexible to easier
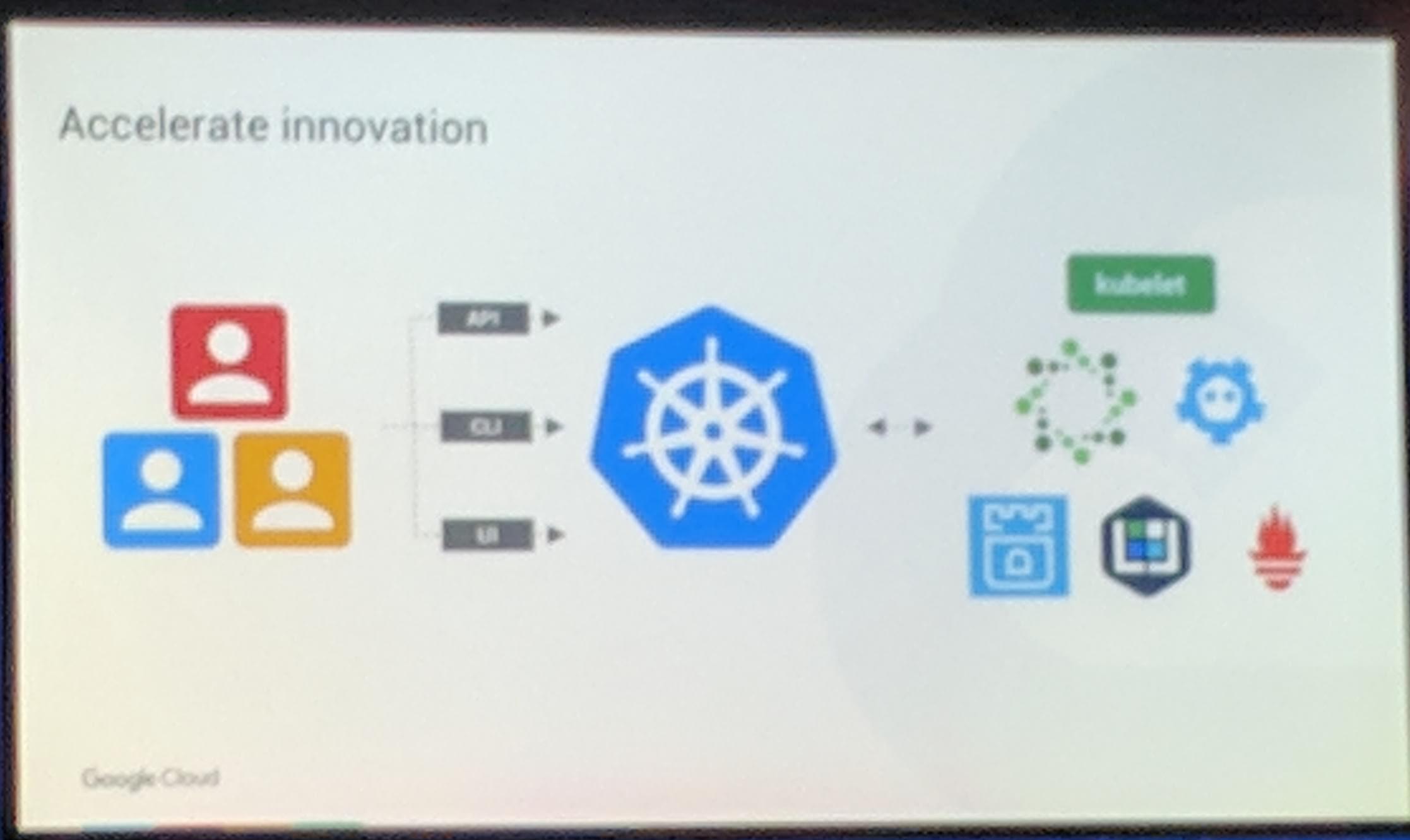
KubeCon: Keynote Rook mentioned on a slide
YES!! Rook again on a slide during the Keynotes. This is awesome, to get recognizition for Rook as an operator at such a big event.
github GoogleCloudPlatform/kube-metacontroller is a project to extend Kubernetes on a meta level through CustomResourceDefinitions.
The kube-metacontroller is a CustomResourceDefinition controller. It is not in the Kubernetes lifecycle, it is an “external” project.
KubeCon: Keynote kube-metacontroller demo
The demo shown was about re-implementing StatefulSets as CatSets with a “custom” specificiation structure.
New features are more likely to come in form of CustomResourceDefinitions from projects of users and companies, and not from Kubernetes directly anymore. Users can now just implement a new feature as they want/need it.
Extensibility is about empowering users. Google and IBM are building Istio using CustomResourceDefinitions to make it easy to use and “integrate” with existing clusters.
Red Hat: Making Containers Boring (again) - Clayton Coleman, Architect, Kubernetes and OpenShift, Red Hat
“Infrastructure allows us to turn the impossible into the ordinary.” Lots of applications in Kubernetes send lots of events in Kubernetes. Red Hat has submitted many issues and pull requests to fix issues with events, metrics and overall running Kubernetes in a “huge” environment.

KubeCon: Keynote Making Kubernetes boring
The release of etcd3 helped fix issues with scaling, as the memory use of etcd went down about -66%. Which is pretty awesome.
“Boring” effectly means a certain maturity of a project and not (always) the death of it.
Pushing the Limits of Kubernetes with Game of Thrones - Zihao Yu & Illya Chekrygin, HBO
Their talk was about the experience with Kubernetes at HBO.
Even a cloud, like AWS or GCE, has limits in the end.
One of the reasons why they use Kubernetes is that the “Batteries are included”, “everything” can be switched out. They are using Terraform to create their Kubernetes clusters on top of their cloud provider. They have a fixed number of masters, a failed one will be replaced. Nodes are up’n’down scaling all the time. Still in the begining some issues, like Prometheus pod is rescheduled on scale down. They register their minons with taints depending if their were either more of scaled instance or there by “default”/reserved. Additionally they have backup minions (not sure if so, but maybe they are cluster independent at least per region) if there is no more instance type available (to be honest this kind of sounds like hoarding of resources). Service Types in Kubernetes may have some problems in “high” load clusters:
type: ClusterIP+Ingresshave problems keeping up with burst traffic spikes.type: LoadBalanceris limited by the AWS/cloud providers API rate limits.
They had the best experience with type: NodePort and using ELBs that have been “manually” (not through Kubernetes) setup.
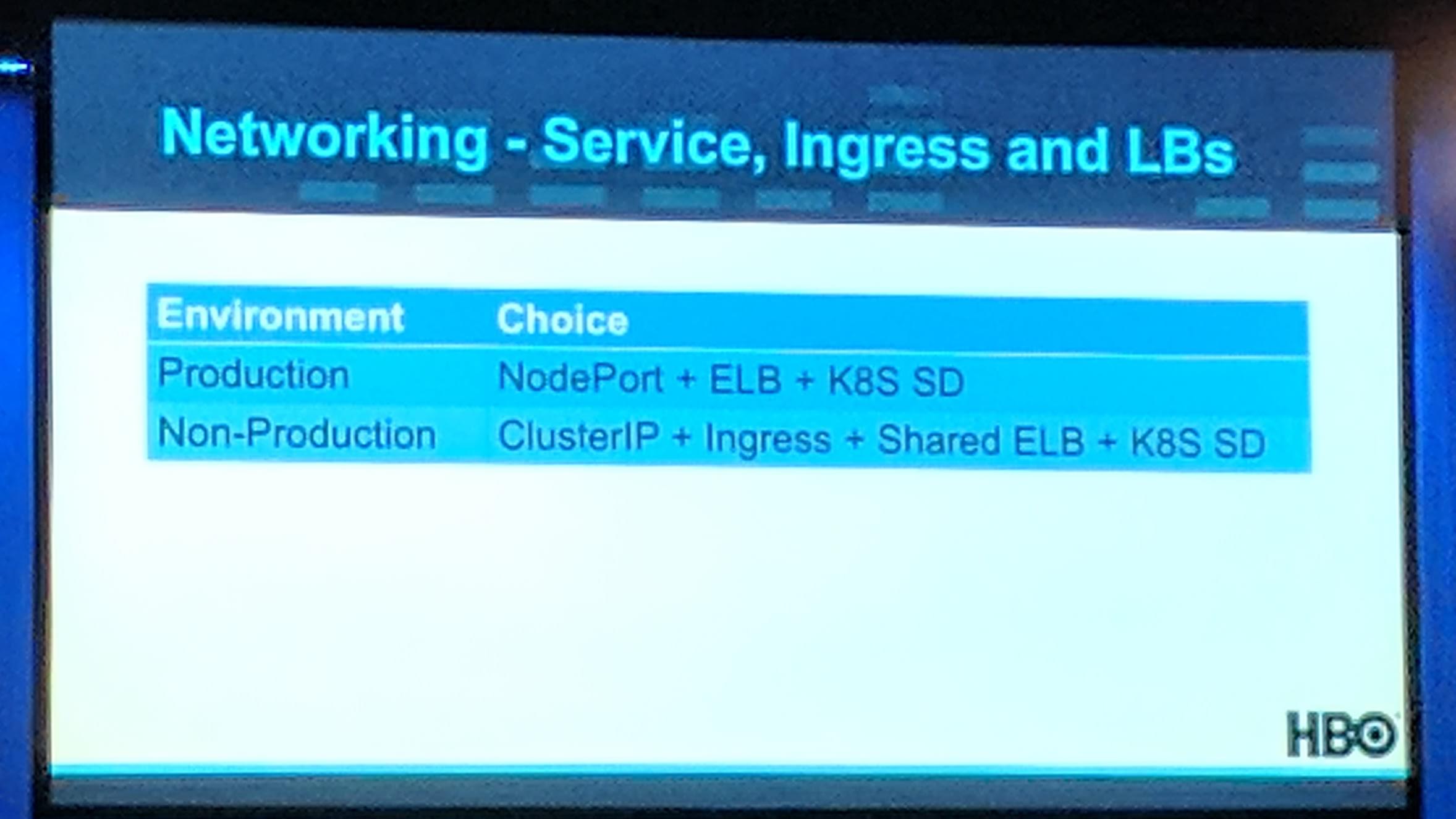
KubeCon: Keynote Networking Services
Flannel has problems scaling beyond a certain point. There are multiple issues open at the Flannel project to look further into these issues, most of the issues have already been resolved.

KubeCon: Keynote Flannel scaling problems
DNS ndots:5 has some issues because it creates a lot of “bad” requests. The image shows all possibilities the name pgsql.backend.hbo.com would take:
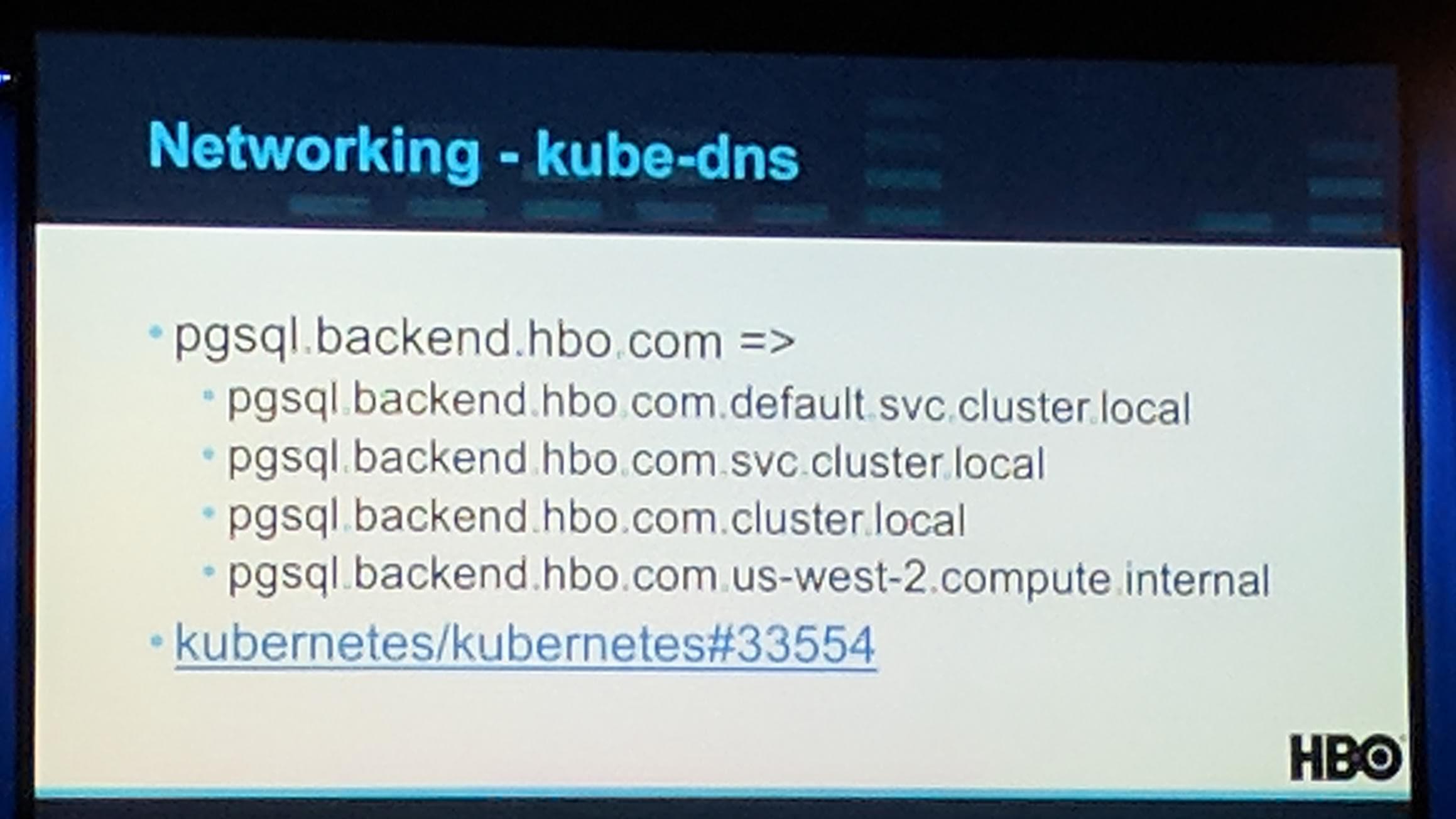
KubeCon: Keynote kube-dns ndots issue
To improve this you can tune kube-dns by adding flags like --cache, --address and --server=/homeboxoffice.com/10.1.2.3#53. More details about tweaking kube-dns in general can be found at Spencer Smith’s blog post KubeDNS Tweaks for Performance.
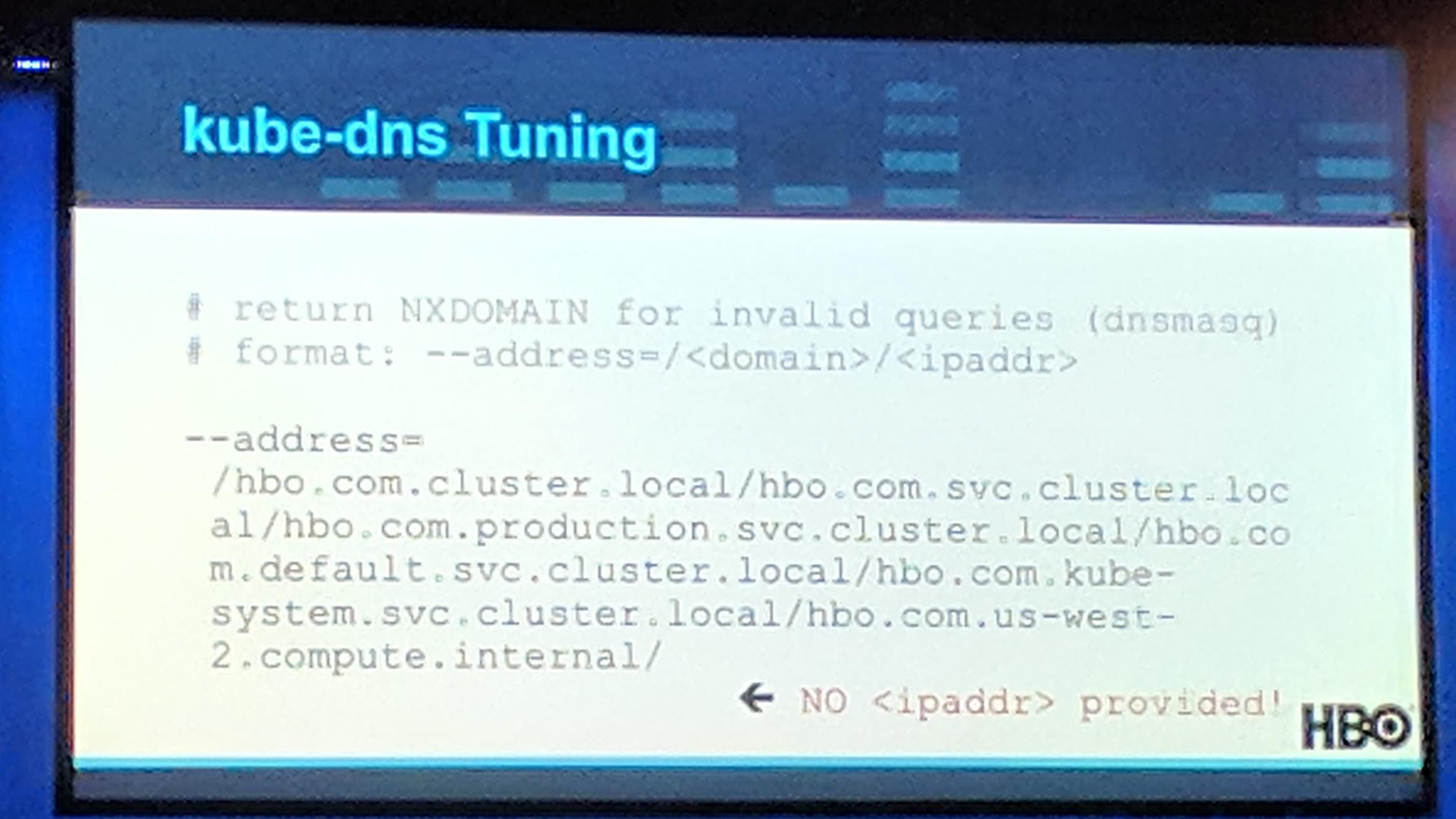
KubeCon: Keynote kube-dns tunning
Using Prometheus and cAdvisor is not that performant/“good” of an idea with 300 and more nodes with every node having 40 cores each and over 20k containers running in the cluster.
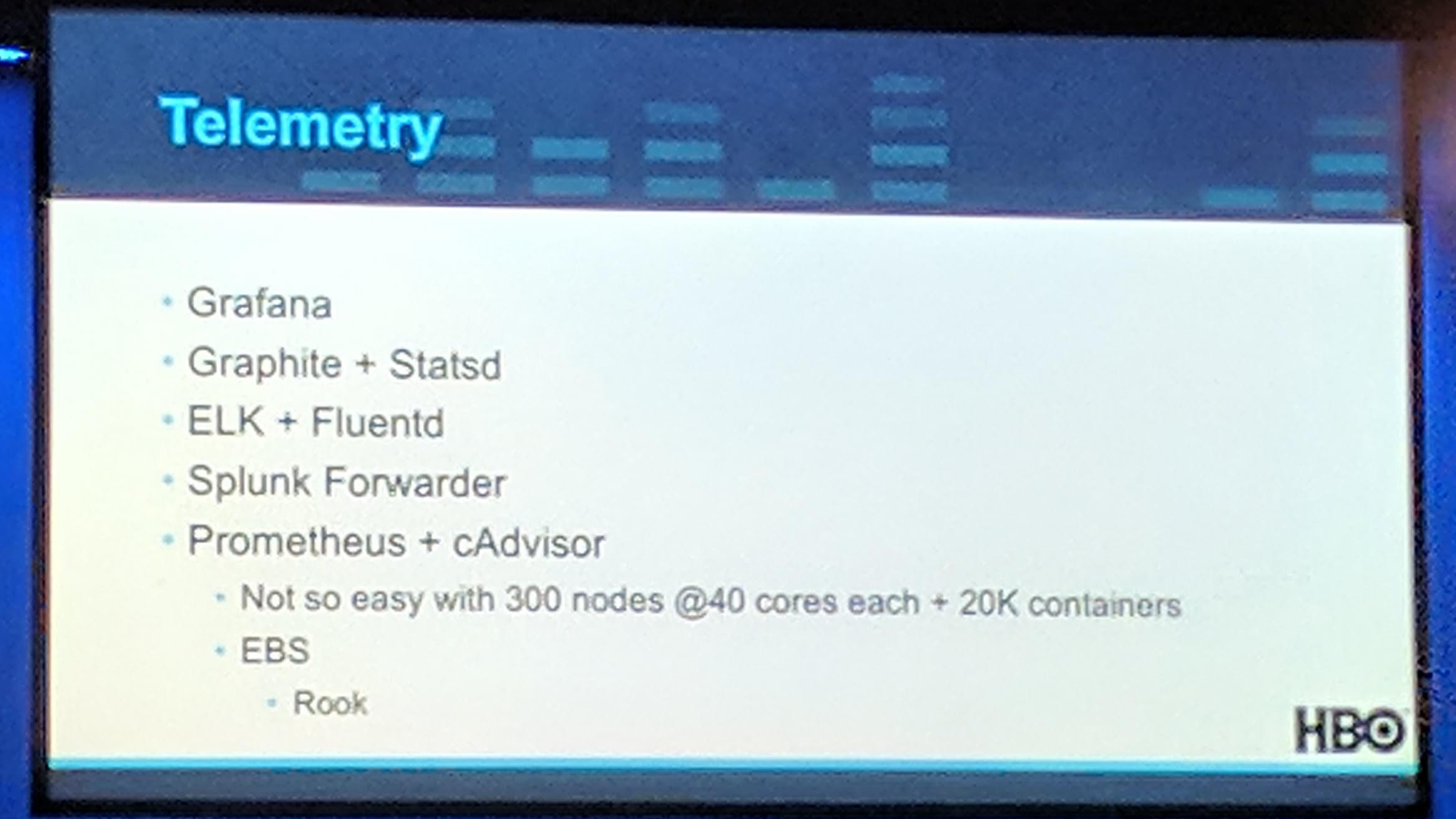
KubeCon: Keynote Kubernetes Telemetry
HBO’s advice:
“Were We Ready?”:
- Load test
- Load test more!
- Load test the SHIT Out of it!!! - HBO

KubeCon: Keynote HBO's advice
Progress Toward Zero Trust Kubernetes Networks - Spike Curtis, Senior Software Engineer, Tigera
Most clouds use Calico Project for their network security policy application. Modern attacks have become more sophisticated.
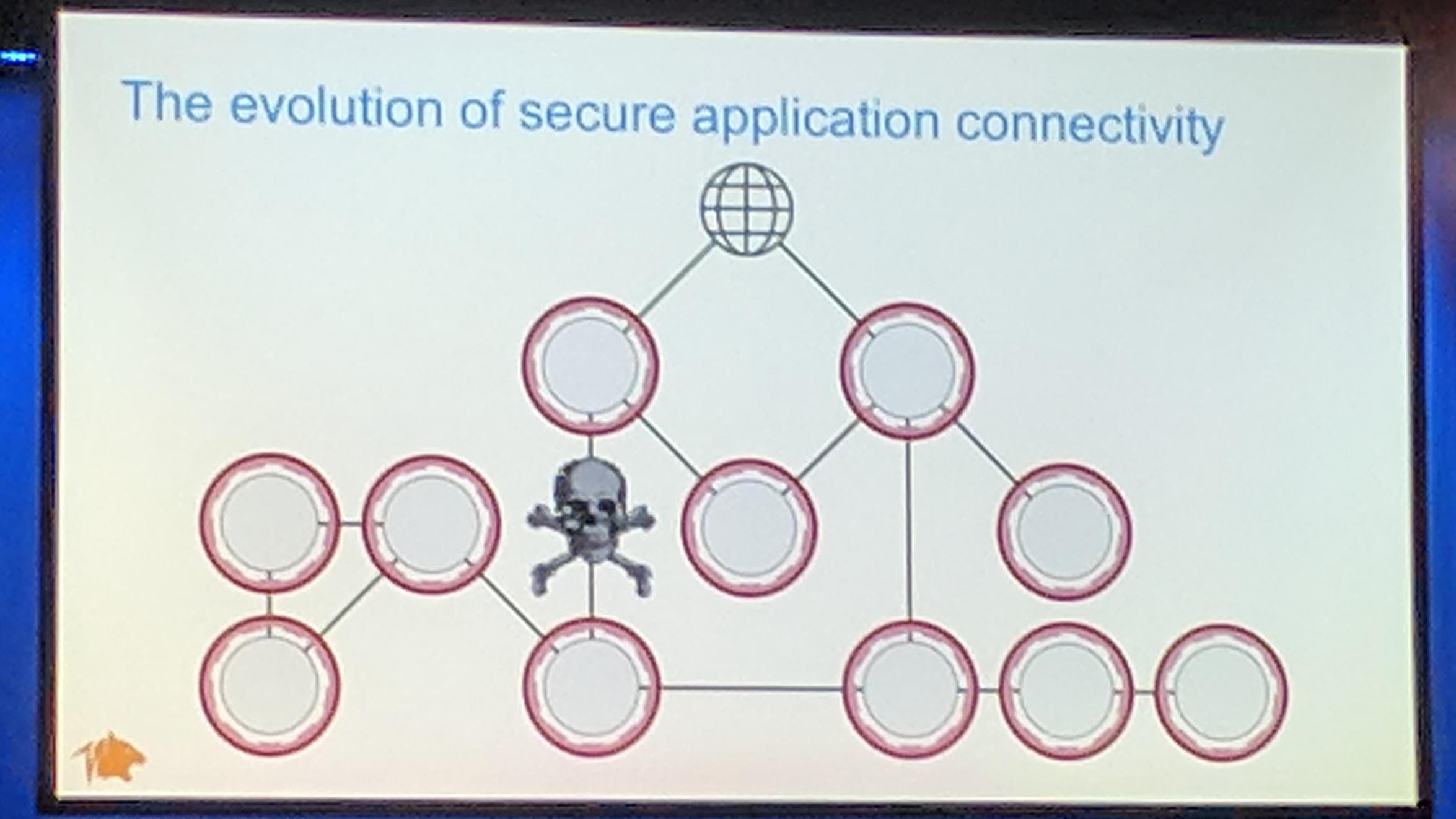
KubeCon: Keynote evolution of secure application connectivity
One way to better protect against attacks, is to do network segmentation.
Isitio handles it transparently for applications.
They announced that Calico support for Kubernetes network security policy and Istio service mesh.
Kubernetes already allows authentication through ServiceAccounts token which would allow each Pod to authenticate itself.
By reducing the trust (network segmentation) in the network the security is increased. Also named Zero Trust network model. github.com projectcalico/app-policy Tigera announced Tigera CNX which is for especially targeted to businesses that want a secure application connectivity platform.
The Road Ahead on the Kubernetes Journey - Craig McLuckie, CEO, Heptio

KubeCon: Keynote Road Ahead on the Kubernetes Journey Shot #1
“The community gotta figure it (/the future) out”
If a developer needs to wait days to get a virtual machine to develop, the productivity is in the cellar. Development productivity is important for both the company and the developer. A cloud world kinda consists of everything “Everything as a Service”. In a world of microservices disaster recovery is very important, when a lot of services depend on each other it is important to correctly do a disaster recovery.

KubeCon: Keynote Seperation of concerns
Most cloud providers want/have a upstream conformance Kubernetes as a Service. The Kubernetes always works everywhere the same, which is good for us the people. That is what a tool like Heptio Sonobuoy is for, running/packaging (conformance) tests to run on multiple cloud providers with ease. Having the possibility for multi-cloud is the dynamic to move between clouds and get what you need, where you want. Heptio is working with Microsoft to bring their project Ark disaster recovery and portability to Microsoft Azure. Ark seems to be a shot worth to look into for disaster recovery of Kubernetes (and storage in Kubernetes). The storage part is still more or less work in progress depending on where you are running your Kubernetes cluster. There is already support for some clouds like AWS and GCE, with Azure coming up through the cooperation with Microsoft.
“Enterprise is.. complicated” because there is no “one” tool for example Ingress, Logging, Monitoring, CI/CD, Security and Stateful services that everyone uses right now. Additionally the politics and “rules” in each company are always different, and at least for a platform like Kubernetes a formalization of extensibility is good to do. Companies using Kubernetes are making it easier for new employees to faster begin working and be productive. This still depends on how they allow access to Kubernetes and how the rollout/deployment of applications is done but still through tools like Helm or good old manifests it is easier.
Talks
Extending Kubernetes 101 [A] - Travis Nielsen, Quantum Corp
Kubernetes resources are declarative. You want a namespace, you get a namespace.
When wanting to declare your own resources, CustomResourceDefinitions (CRDs) are what you want to do. To note for CustomResourceDefinitions they use the same pattern as the built-in resources.
You declare it and the “owner” in the Kubernetes cluster of the CustomResourceDefinition controller makes it happen.
The traditional approach is to create a REST API “outside” of Kubernetes. This isn’t a good way to run something “Kubernetes-native”.
The CustomResourceDefinition objects are as simply edited as every other object in Kubernetes.
Using Kubernetes objects directly is way better for Devs and Ops to use, as it streamlines the way to use something in the “Kubernetes way” (manifests).
When developing CustomResourceDefinitions you should design the CustomResourceDefinition properties. Additionally in Kubernetes 1.8+ there is code generation available to make resources available to clients to use/consume better.
The flow of an operator is like:
- Design the
CustomResourceDefinitionproperties. - Register the
CustomResourceDefinitionat the API server. - Run a watch loop on your
CustomResourceDefinition. - On events to the
CustomResourceDefinition, trigger defined functions/methods.
An example CustomResourceDefinition could look like this:

KubeCon: Talk Extend Kubernetes example CustomResourceDefinition
It can has any kind of structure as long as it can be done with a YAML file.
The code of the sample operator shown is available at GitHub rook/operator-kit - /sample-operator directory.
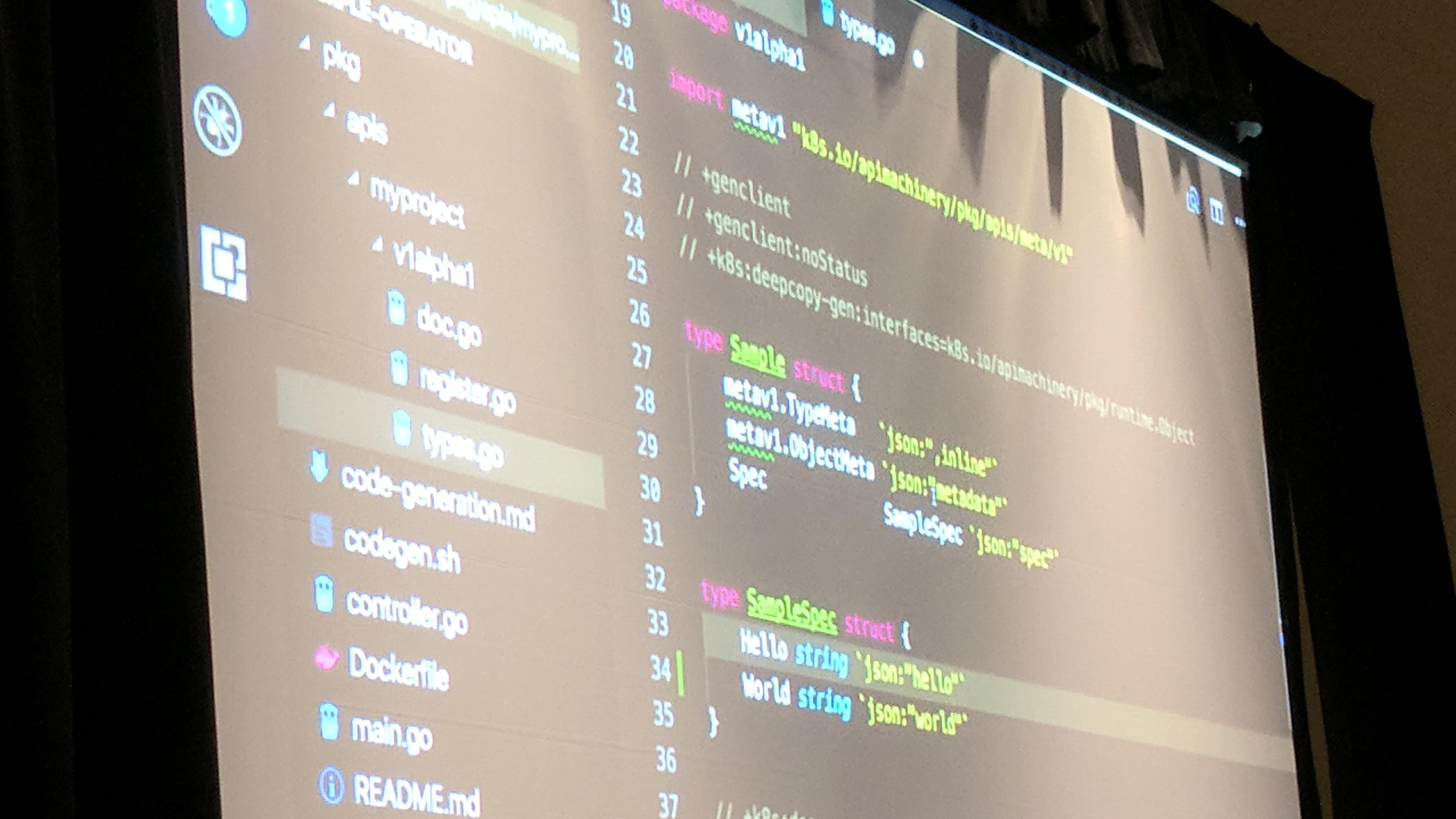
KubeCon: Talk Extend Kubernetes example CustomResourceDefinition Go code structure
In Go to pickup a CustomResourceDefinition for (automatic) code generation, you just add annotations in the code.
Additionally to be able to list each CustomResourceDefinition, a CustomResourceDefinition structure with an “array”/list type of the CustomResourceDefinition should be also created.
As written in the fourth point in the operator flow, an operator reacts on events such as Add, Update and Delete during the watch of the CustomResourceDefinitions.
The operator should should “include” the code generated by the Kubernetes CustomResourceDefinition generation tool.
An operator kit is useful to not write the same code for handling CustomResourceDefinitions over and over again, for example GitHub rook/operator-kit.
Rook was named as example (with it’s operator-kit, see link above):

KubeCon: Talk Extend Kubernetes Rook project
Building Helm Charts From the Ground Up: An Introduction to Kubernetes [I] - Amy Chen, Heptio
Helm is like a “version control system” for Kubernetes manifests. Instead of “normal” Kubernetes only allows to rollback certain types of objects, like Deployments. Helm allows to rollback more than that through versioning of manifest as “bundles”.
It even simplifies installing, upgrading of objects in Kubernetes that have been created through Helm.
Vault and Secret Management in Kubernetes [I] - Armon Dadgar, HashiCorp
Application requests Credentials -> Vault -> Create Credentials in Database
Application <- Vault <- Return created Credentials to Application
How Dynamic secrets should be handled in Vault:

KubeCon: Talk Vault Management Kubernetes Dynamic secrets
To be able to dynamically create credentials on demand, there are plugins available that are separate from the core.
These plugins are available for multiple applications like MySQL, SSH and more. This is kinda more of a community “thing” to create more and more plugins/integrations for applications.
High availability is achieved by a active<->standby model. The standby instances proxy the requests to the active instance.
A bit about some of the features in Vault: Entities are a reprensentation of a signle person which is consistent across logins. Alias allow a mapping between an entity and an auth backend. Identity Groups allow a “team sharing” like structure, example:
- Development -> consists of Team ABC and Team XYZ
- Ops -> consists of Team DEF and TEAM XYZ
Vault has a Kubernetes authentication backend for authentication with Service Accounts from Pods, see https://www.vaultproject.io/docs/auth/Kubernetes.html.
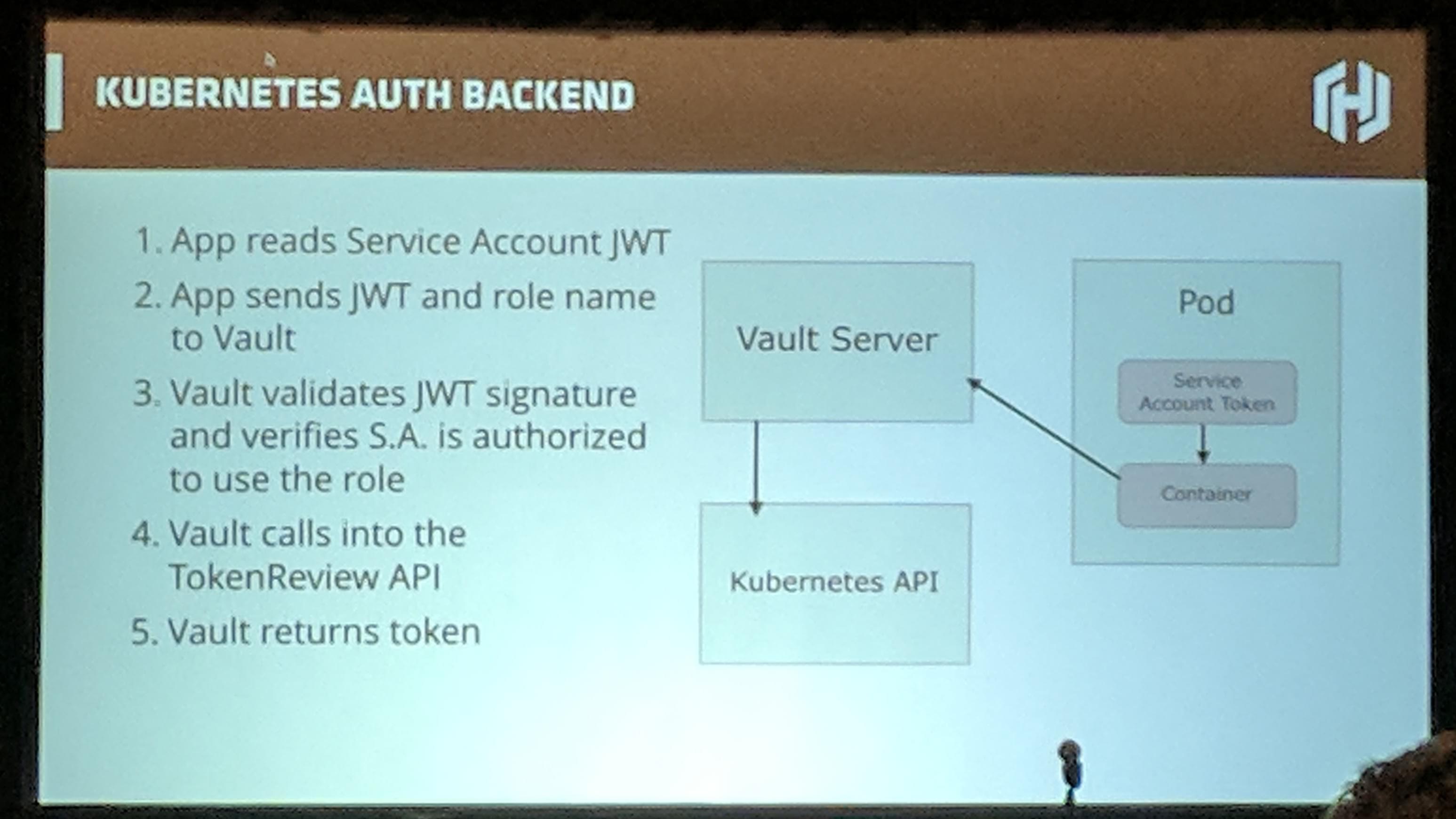
KubeCon: Talk Vault Management Kubernetes Auth Backend
Lunch time: Tacos by RedHat
This is my mandatory food shot. Thanks for the Tacos to RedHat, Inc. - @RedHatNews!

Day #3
Keynotes Morning

KubeCon: Keynote Day #3 Shot #1
Opening Remarks + Keynote: Kubernetes Community - Sarah Novotny, Head of Open Source Strategy, Google Cloud Platform, Google
There was snow yesterday, which is pretty rare in Texas and especially in Austin.
KubeCon is a huge event, is it still the community I love? Who has the power? Who to ask? Steering Committee!
“Culture eats strategy for breakfast.” - Ptere Drucker From 400 two years ago to this year huge increase.
Distribution > Centralization

KubeCon: Keynote Opening Remarks #1
Inclusive > Exclusive It’s a core piece.

KubeCon: Keynote Opening Remarks #2
Community > Company A culture of contious learning.
KubeCon: Keynote Opening Remarks #3
Improvement > Stagnation

KubeCon: Keynote Opening Remarks #4
Automation > Process
There is a “Manual labor tasks, chop wood, carry water” award which has been given out at the first day before the party.

KubeCon: Keynote Opening Remarks #5
Love Kubernetes, shape the industry.

KubeCon: Keynote Love Kubernetes, shape the industry
Kubernetes at GitHub - Jesse Newland, Principal Site Reliability Engineer, GitHub

KubeCon: Keynote Day #3 Shot #2
GitHub and GitHub API production are running on Kubernetes. At the time (4 years ago) it seemed “impossible” to run applications in containers. Keep in mind that projects like Kubernetes didn’t exist back then. Seniors at GitHub said wait for it:
“We’re not the right spot to do the execution”
They were really not in the right place and time to do that.

KubeCon: Keynote GitHub Love Kubernetes
They already have about 20% of their services running in Kubernetes. GitHub.com and the GitHub API are already powered by Kubernetes (at least the stateless part of it).
KubeCon: Keynote GitHub over 20% services on Kubernetes
There was no real experience operating Kubernetes clusters. Multiple clusters in different sites are used. Their existing deployment tools are used to deploy to their multiple sites. An interesting aspect from the hardware side is that they use small “blade” like servers, see next image.

KubeCon: Keynote GitHub blade servers
And their current clusters look like this:

KubeCon: Keynote GitHub Cluster configuration
ChatOps is used to deploy by chat. Hubot is used for the chat commands. They are also using Puppet for deploying to Kubernetes. That they use Puppet is pretty interesting as most people seem to try to get away from Puppet when switching to a platform like Kubernetes. They use a construct of Consul + templating to “route” the traffic to the correct destination.
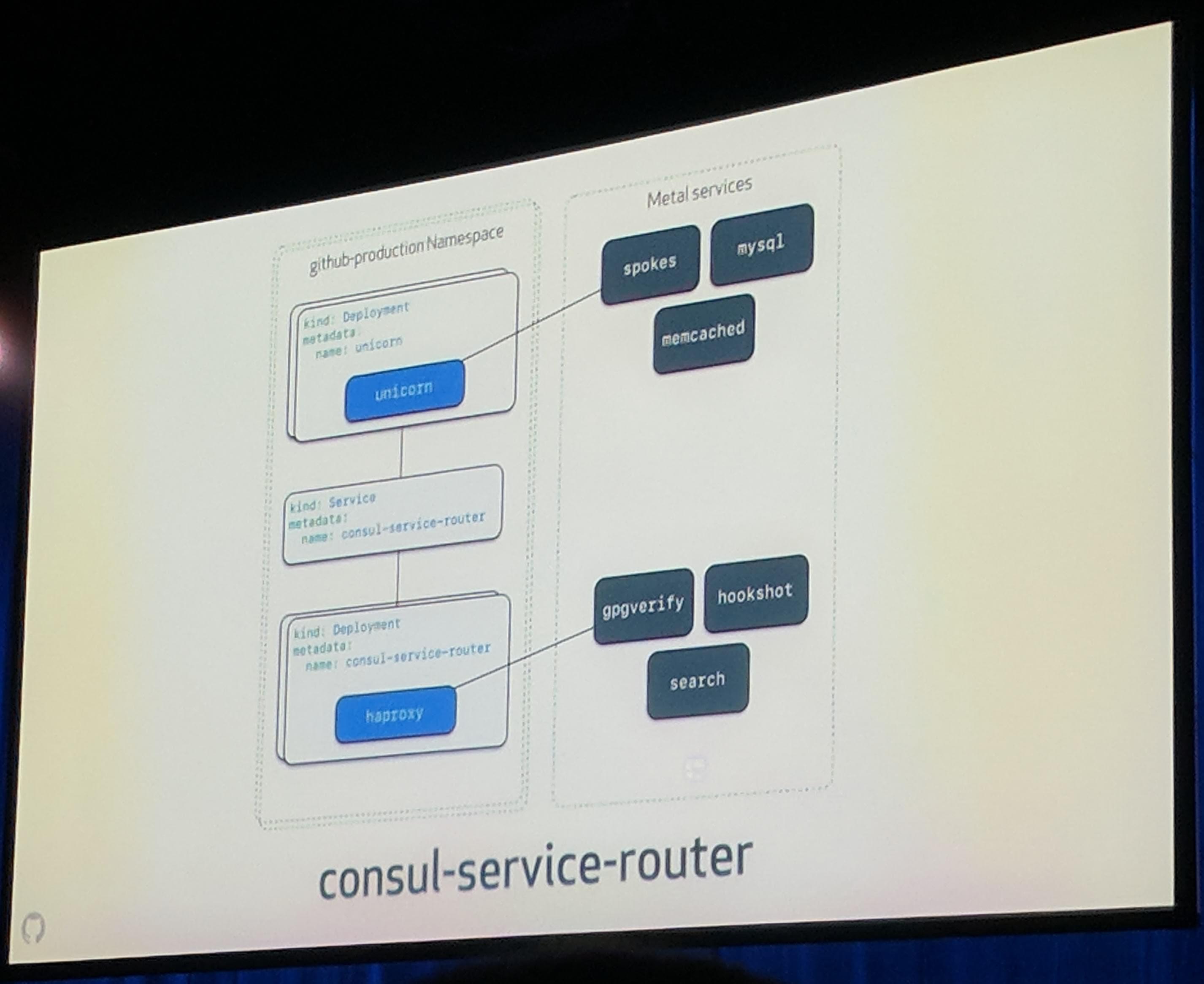
KubeCon: Keynote GitHub consul service router
They hope to replace their self built construct with the Enovy proxy project soon.
GLB (GitHub LoadBalancer) is used for load balancing and to expose the services to the load balancer NodePort is used.
Awesome tools have been created:

KubeCon: Keynote GitHub Awesome tool
Workflow Conventions have been set. This allows everyone to be on the same page for development and deployment which in return allows for increased development effiency and faster deployments.

KubeCon: Keynote GitHub Lab Branch Workflow

KubeCon: Keynote GitHub Lab workflow
When a commit is pushed to a pull request a so called “lab” URL is returned. This “lab” URL has a build running with given changes. Every “lab” application has it’s own Namespace which is deleted after 24 hours.
Canary deployments with their routing construct allow them to give small a percentage of traffic a new feature so it can be tested before it is released.
All GitHub services are now using canary deployments.

KubeCon: Keynote GitHub Canary deploy
The plan for GitHub with Kubernetes is to move more and more workload to Kubernetes. They have also plans to get persistent volumes in Kubernetes for their engineers.

KubeCon: Keynote GitHub Kubernetes made it easier for SREs

KubeCon: Keynote GitHub Decomposition of monolith services
Currently most of their used projects aren’t Open Source yet, but they will begin to change that soon. “It is the least we could do for the community” This is a good view on returning to the community and overall open source as a company.
Manage the App on Kubernetes - Brandon Philips, CTO, CoreOS
The goal is to make applications easier to build, deploy, update and “everything”. There is a demand for running more and more applications on Kubernetes, but with moving more applications into Kubernetes you are also more and more accountable for them.
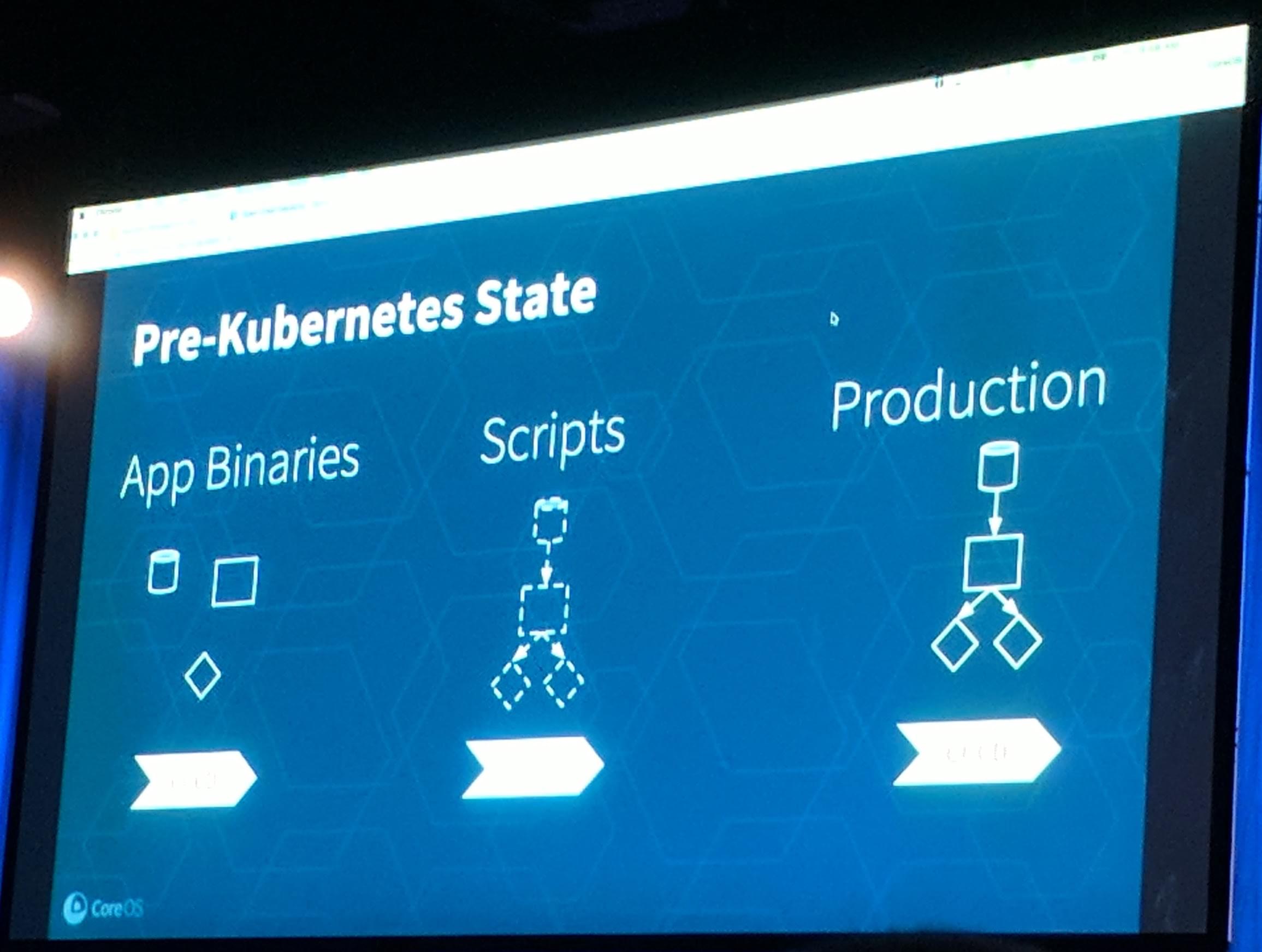
KubeCon: Keynote CoreOS Pre-Kubernetes State for Applications
Who is the owner? Where are the dashboards? Metrics and SLAs? Docs?
An eco system should have a catalog of the applications running, with all information (owner, SLAs, etc) in it.

KubeCon: Keynote CoreOS Future Kubernetes State for Applications
These informations should be moved into metadata of the application (in Kubernetes too). This is partly a vision right now. It is all managed through objects in Kubernetes, which have the advantage that everyone with correct access to Kubernetes can read them. They showed off the Tectonic console which already can manage applications through operators like ETCD, Vault and Prometheus.
What’s Next? Getting Excited about Kubernetes in 2018 - Clayton Coleman, Architect, Kubernetes and OpenShift, Red Hat
How can we make Kubernetes exciting (again)? We, the people, should help make “everything” better (contributing, discussing proposals and issues and engaging in a Special Interest Group).

KubeCon: Keynote Suprise we already are!
But.. if you haven’t been engaged, you should go out of your comfort zone and work with people for projects you haven’t worked with yet.
- Build faster, smarter, better: Set it Open Source, like Ruby on Rails, they have set the tone for creating and sharing (Gems) code. Sharing now enables everyone to build a service mesh.
- 2018 Year of the Service Mesh: Isitio, Envoy, Conduit will help solve this problem/use case. Machine learning is/will be more and more important.
- Serverless? fission, Kubeless, Apache OpenWhisk are some examples for projects that implement serverless.
- Defining Apps: Applications are getting more complex over the years. Helm, kompose, kedge and other applications try helping with making it simpler for complex applications to “exist”.
- Security and Authentication
- Spiffe, Istio and Kerberos for securing workload identity. The working group
container-identity-wgis working on improving that. - Multi-tenancy, Policy through open policy agent (OPA), LDAP,
<INSERT POLICY HERE>. - Better containers (and virtual machines!): CRI-O, containerd, OCI, kubevirt, Hyper-V, debug containers (for debugging in production as an example).
- GitHub appscode/kubed, github.com/heptio/ark github.com/cloudnativelabs/kube-router, github.com/GoogleCloudPlatform/kube-metacontroller
- Spiffe, Istio and Kerberos for securing workload identity. The working group
How do you participate? Build something. Use anything. Help anyone. Talk to people. Create something new!
Hint: But don’t reinvent everything.
What is Kubernetes? - Brian Grant, Principal Engineer, Google
Kubernetes was launched at OSCON. Kubernetes was the most fun for him. I can confirm this!

KubeCon: Keynote Is Kubernetes a...
Pretty good look at more of the Kubernetes technical side.

KubeCon: Keynote Google CaaS
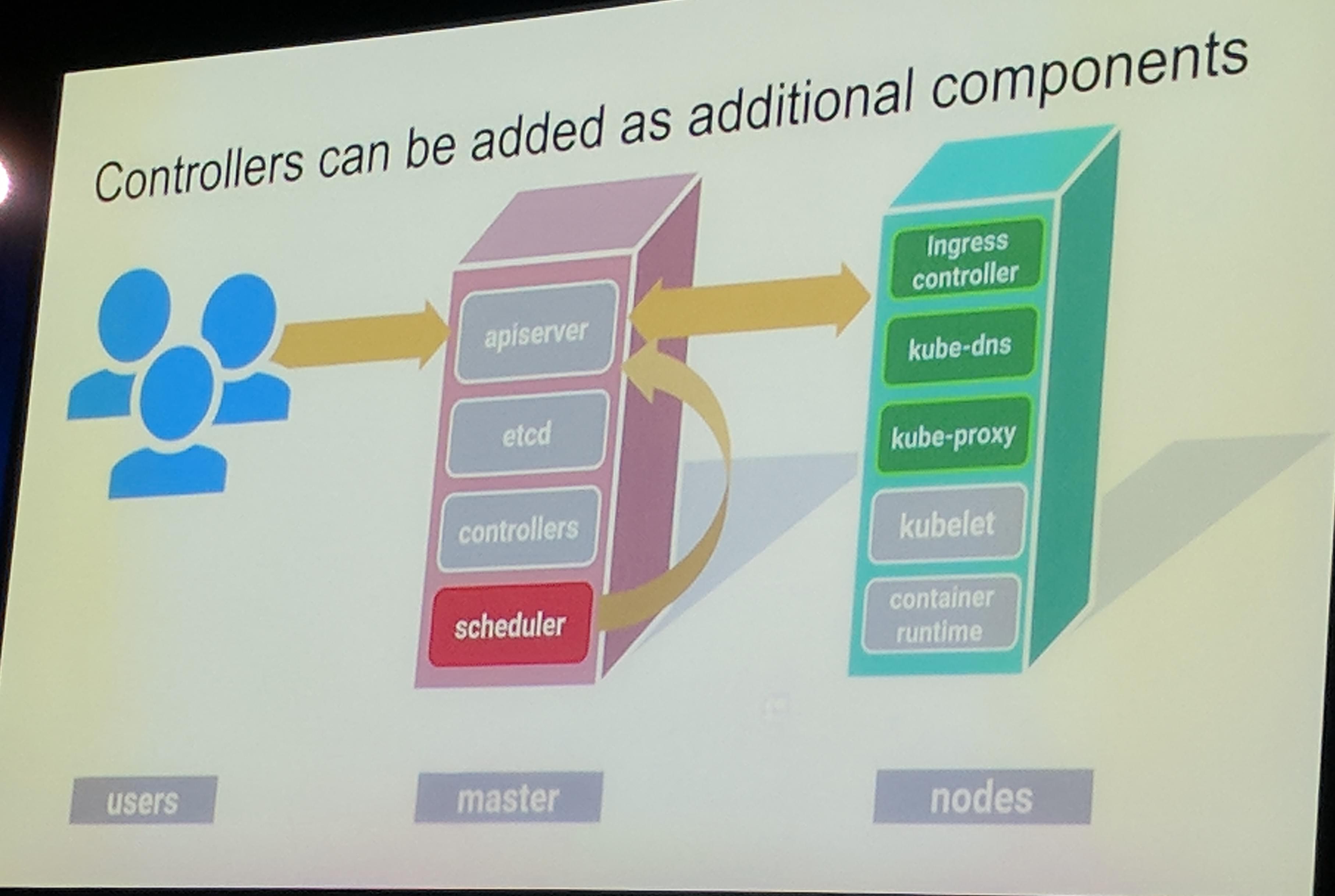
KubeCon: Keynote Google Controllers

KubeCon: Keynote Google SaaS
Nice! Again Rook was named as an example for extending the Kubernetes API (through CustomResourceDefinitions).

KubeCon: Keynote Google Kubernetes Extension Examples
“As long as it implements the API, it is/should compatible”
Kubernetes can be used for automating management, Service Catalog APIs.
Kubernetes is kind of a portable cloud abstraction.
Kubernetes shouldn’t do everything you want! You can build your own tools to do that on Kubernetes, like with CustomResourceDefinitions. SDKs are under development to make creating APIs even simpler and easier.
Conclusion is that Kubernetes is awesome!

KubeCon: Keynote Google Conclusion of Talk
Talks
Disaster Recovery for your Kubernetes Clusters [I] - Andy Goldstein & Steve Kriss, Heptio
A big problem in Kubernetes about disaster recovery is stateful data. Stateful data already begins with the etcd data for Kubernetes and goes down to the PersistentVolumes used inside Kubernetes.
For etcd you can do backups on block, file, etcdctl or Kubernetes API discovery level.
For Persistent Volumes there is currently nothing really for backing them up, except for cloud providers as they most of the time have a volume snapshot API. But there is on going work for a snapshot/backup API in Kubernetes in some way. From my perspective it is likely that this will be added to the Container Storage Interface in some way.
Heptio Ark allows to do restore of API objects and PersistentVolumes in Kubernetes. Additionally it is able to backup and restore PersistentVolumes, currently “only” cloud providers such as AWS and GCE. There is on going discussion how to implement backups for example with appscode Stash through Ark.
When using the Kubernetes API Discovery it discovers all APIs available in the Kubernetes API server asked.
An overview of Heptio Ark features are:

KubeCon: Talk Heptio Ark DR Features

KubeCon: Talk Heptio Ark DR Features
The features can be extended through hooks (example a script should be run before a backup is taken) and plugins. There are different types of plugins, which allow different ways to extend Ark with more functionality.
In the demo they used Rook block storage and showed how to backup and restore a PersistentVolume.
It is as simple as running a command to create a scheduled backup. When for example deleting a namespace with a PersistentVolumeClaim, it allows to fully recover the Kubernetes objects (new UIDs though) of the PersistentVolume and the content PersistentVolume itself too.
As noted earlier the support for the content of a PersistentVolume is mostly for cloud providers, but there is work done already for that in heptio/ark Issue 19 - Back up non-cloud persistent volumes.
A great point about Ark, is that it is open source. To communicate with the Ark (/Heptio) team fast, they have a channel in the Kubernetes Slack #ark-dr.
One Chart to Rule Them All: Continuous Deployment with Helm at Ticketmaster - Michael Goodness & Raphael Deem, Ticketmaster
No “Lord of the Rings” memes, even when the title suggests it. There is no native way to bundle every “dependent” resource together, to make creating/updating/deleting simpler for application deployments. Helm is like a package manager for applications on Kubernetes. When you have a lot of clusters and multiple stages a tool like Helm makes it easier for teams to package their applications (for each stage). They also use a tool to create namespaces, which adds some metadata to it, RBAC, resource quotas and network policies automatically.

KubeCon: Talk One Chart - Versions
I personally prefer a mix of both ways, as some teams just want to have stuff like they want it to and that is just how it is right now that some teams like it their own way. Taking that “freedom” away wouldn’t be that good for existing teams that work like that (where no standard is set in the company).
Looking at Springboot applications v2 looks like the better approach for it, but it also depends on what kind of (Springboot) application you want to deploy.
In v2 having a lot of knobs and dials, can be considered good depending on how experienced the team(s) are with those features controlled by the dials and knobs.
Knobs for stuff like tracing, logging and other sidecar/features is nice to have in the templates.
But covering everything is never possible so only the most important functions should be “exposed” as values in the values.yaml.

KubeCon: Talk One Chart - Chart Shot #1
KubeCon: Talk One Chart - Chart Shot #2
KubeCon: Talk One Chart - Chart Shot #3
They have a pretty awesome (and complex) looking Helm Chart “Template” for their so called “Webservice” (chart).
It has many features to simply be toggled through the values.yaml.
Economics of using Local Storage Attached to VMs on Cloud Providers [I] - Pavel Snagovsky, Quantum

KubeCon: Talk Local Storage Shot #1
Locally attached storage is most of the time faster and mostly inexpensive (depending on your (cloud) provider).

KubeCon: Talk Local Storage Pros & Cons
Using an application like Rook to utilize that storage would be a good possibility to use that fast storage overall for the Kubernetes, in the cluster.

KubeCon: Talk Local Storage Harnessing the benefits with Rook
Rook solves the problem of local storage going to waste (by not being used) and instead utilizes it as written earlier to be used in Kubernetes for Kubernetes. The performance is in some cases better with Rook instead of using a cloud provider of choice block storage. For AWS a performance comparison can be found in this Rook blog post and the charts can be seen in the next photo:

KubeCon: Talk Local Storage AWS performance comparison
Another advantage when taking a look at using Kubernetes in multiple cloud environments, is that Rook is compatible with Kubernetes and has only a small amount of requiremenets for it to run, making it easier to migrate/move data between clouds (an example for migrating data would be heptio/ark or appscode/stash).

KubeCon: Talk Local Storage Rook Compatibility
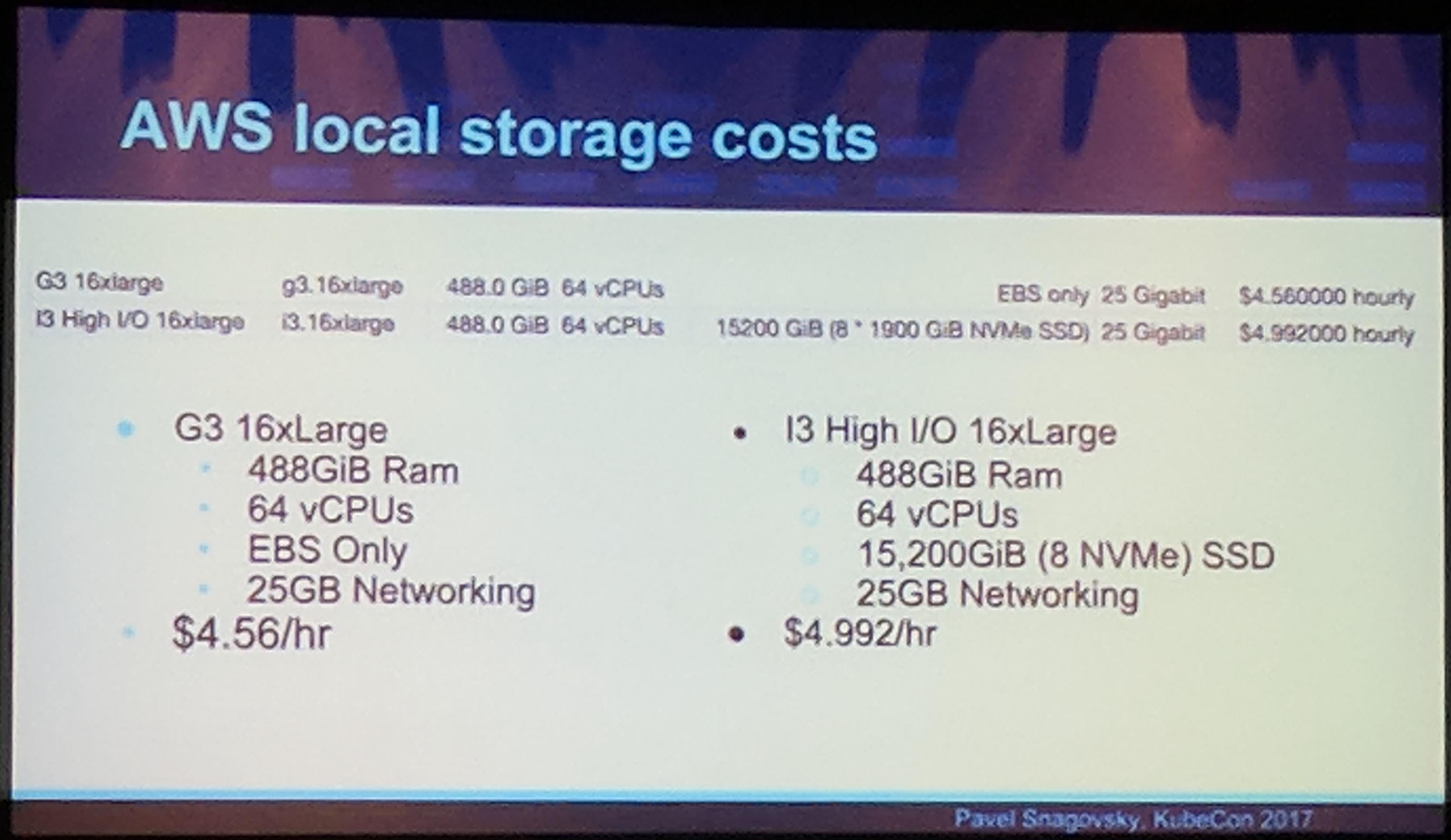
KubeCon: Talk Local Storage AWS Local Storage costs

KubeCon: Talk Local Storage Costs Summary
Use cases for Rook are:
- Use the Rook object store instead of the cloud provider ones (overall running services yourself, may lower the cost for you if the administration knowledge is existing).
- Multiple clusters for different performance and isolation requirements are possible.
- Kubernetes integration allows a simple switch to Rook as it “exposes” storage through Kubernetes native
StorageClasses. - And many more..

KubeCon: Talk Local Storage Conclusion
Rook is awesome! But keep in mind that, as always, it is dependent on if it really fits your specific use case. Depending on what your use case is in the cloud or on bare metal, you could save money for certain use cases.
“Find A Job | Post A Job | Get Involved” Wall

KubeCon: Sponsor Showcase Find A Job | Post A Job | Get Involved Wall
If you need more pixels, I can help you as I still have the photo in original resolution available, please send me an email about it. Thanks!
Summary
My first travel to the USA, my first KubeCon, it was awesome! I have met a lot of awesome people and it was especially nice to see the Rook team and community. I hope to see a lot of those awesome people at the next KubeCon in Copenhagen.
Have Fun!
P.S.: Please let me know (by comment or email), if there is anything I can improve to make this post about the conference even better. Thanks for reading!